知识拓展主要分为以下几个部分:
- 深入理解LinkedHashMap
- LinkedHashMap 与 Lru(Least recently used,最近最少使用)算法
- Android LruCache
- Glide LruCache
一、深入理解LinkedHashMap
在本章节理解LinkedHashMap 将分别按以下几点展开:
- 1.1、LinkedHashMap 概述
- 1.2、LinkedHashMap 在 JDK 中的定义
- 1.3、LinkedHashMap 的构造函数
- 1.4、LinkedHashMap 的数据解构
- 1.5、put和 get 操作
1.1、LinkedHashMap 概述
HashMap 是 Java Collection Framework 的重要成员,也是Map 族(如下图)中我们最常用的一种。HashMap 是无序的,也就是说,迭代HashMap 所得到的元素顺序并不是它们最初放置到HashMap 的顺序。
HashMap 的这个缺点往往早晨诸多不便,因为在一些场景中,我们确实需要用到一个可以保持插入顺序的Map。庆幸的是,JDK 为我们解决了这一问题,提供了一个HashMap 的子类——LinkedHashMap。虽然 LinkedHashMap 增加了时间和空间上的开销,但是它通过维护一个额外的双向链表保证了迭代顺序。
该迭代顺序可以是插入顺序,也可以是访问顺序。因此,根据链表中元素的顺序可以将 LinkedHashMap 分为: 保持插入顺序LinkedHashMap 和 保持访问顺序的 LinkedHashMap,其中LinkedHashMap 的默认实现是按插入顺序排序的。
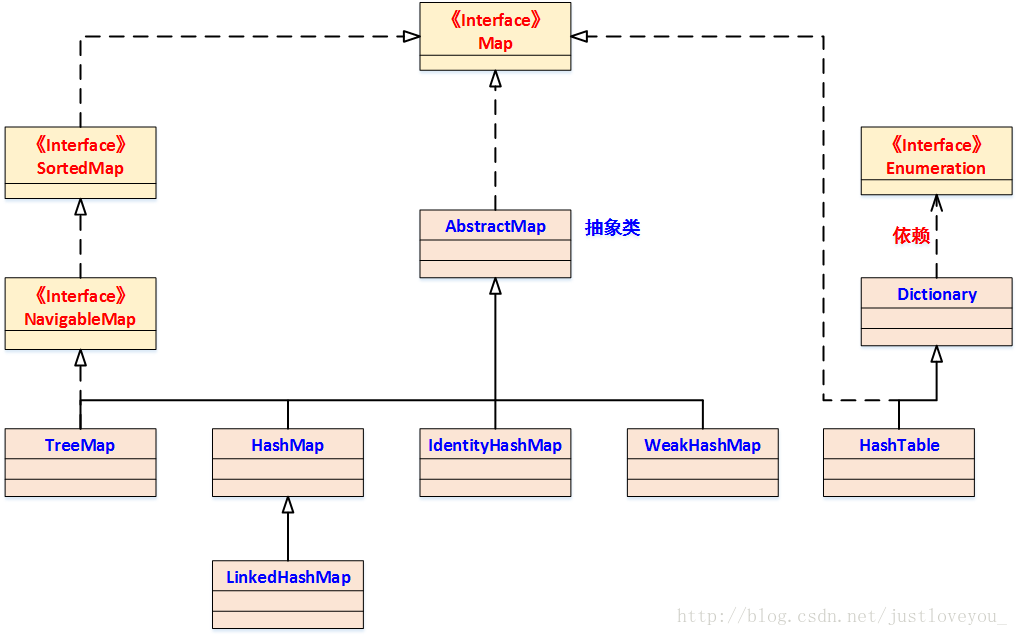
Entry 的继承图如下
本质上,HashMap 和双向两边合二为一即是LinkedHashMap。所谓LinkedHashMap,其落脚点在HashMap,因此更准确地说,它是一个将所有Entry节点链入一个双向链表的HashMap。
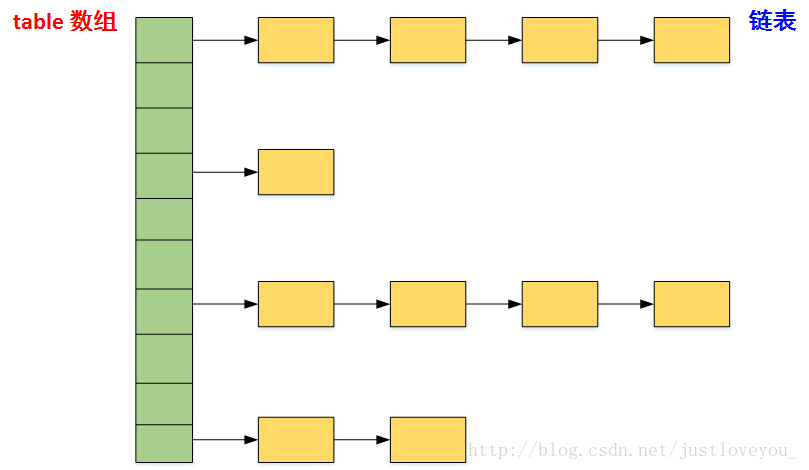
在LinkedHashMap 中,所有put进来的Entry 都保存在如下图所示的哈希表中,但由于它有额外定义了一个以 head 为头节点的双向链表(如下图所示),因此对于每次put进来Entry,除了将其保存到哈希表中对应得位置之上外,还会将其插入到双向链表得尾部。
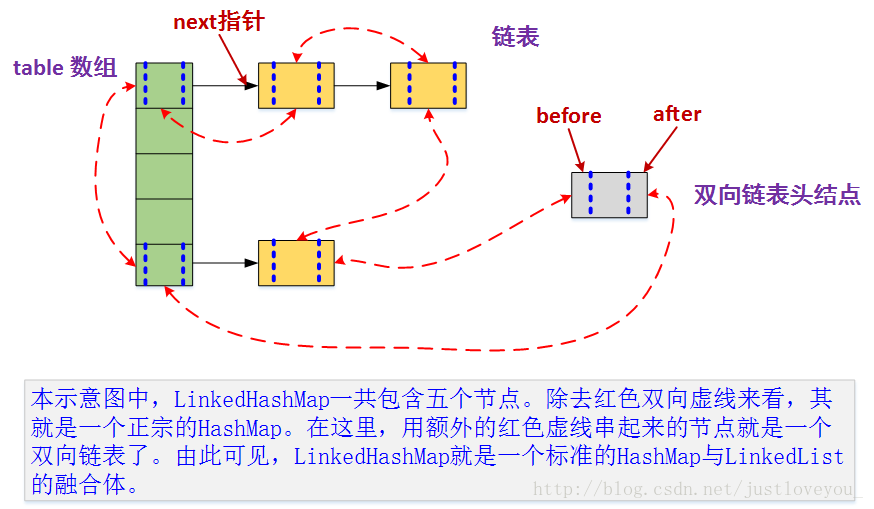
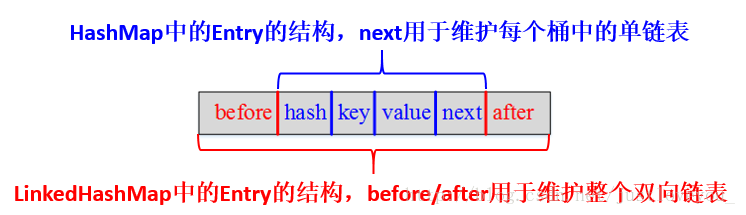
更直观地,下图很好的还原了 LinkedHashMap 的原貌:HashMap 和双向链表的密切配合和分工合作早就了 LinkedHashMap。特别需要注意:next 用于维护 HashMap 各个桶中的Entry 链,before、after 用于维护 LinkedHashMap 的双向链表,虽然它们的作用对象都是 Entry,但是各自分离,是两码事。
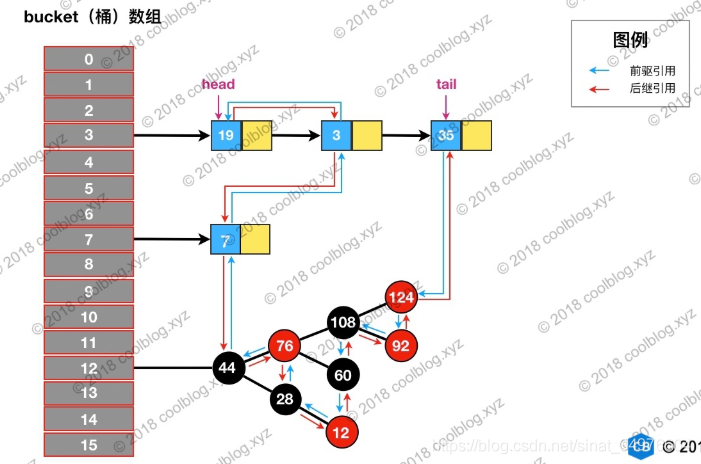
HashMap 与 LinkedHashMap 的 Entry 结构示意图如下:
由于 LinkedHashMap 是 HashMap 的子类,所以 LinkedHashMap 自然会拥有 HashMap 的所有特性。比如:LinkedHahsMap 也最多只允许一条Entry的键为Null(多条会覆盖),但允许托条Entry的值为Null
LinkedHashMap 也是Map 的一个非同步的实现,此外,LinkedHashMap 还可以用来实现 **LRU(Least recently used, 最近最少使用)**算法。
1.2、LinkedHashMap 在 JDK 中的定义
1.2.1、类结构定义
LinkedHashMap 继承于HashMap,其在JDK中的定义为:
1 | public class LinkedHashMap<K,V> |
1.2.2、成员变量定义
与HashMap 相比,LinkedHashMap 增加了两个属性用于保证迭代顺序,分别是双向链表头结点header 和 标志位 accessOrder(值为true 时,表示按照访问顺序迭代;值为 false 时,表示按照插入顺序迭代)。
1 |
|
1.2.3、成员方法定义
从下图可以看出,LinkedHashMap 中并没有增加额外的方法。也就是说,LinkedHashMap 与 HashMap 在操作上大致相同,只是在实现细节上略有不同。

1.2.4、基本元素Entry
LinkedHashMap 采用的hash 算法和 HashMap相同,但是它重新定义了Entry。LinkedHashMap 中的Entry 增加了两个指针 before 和 after,它们分别用于维护双向链表。需要特别注意的是:next 用于维护HashMap 各个桶中Entry 的连接顺序,before、after 用于维护Entry 插入的先后顺序。代码如下:
1 | static class Entry<K,V> extends HashMap.Node<K,V> { |
HashMap与 LinkedHashMap 的Entry 结构示意图如下:
1.3、LinkedHashMap 的构造函数
1.3.1、LinkedHashMap(int initialCapacity,float loadFactor, boolean accessOrder)
LinkedHashMap 一共提供了五个构造函数,它们都是在HashMap 的构造函数的基础上实现的,处理默认空参构造方法。如下这个构造函数包含了大部分其他构造方法使用的参数,就不一一列举了。
1 | public LinkedHashMap(int initialCapacity, |
该构造函数意在构造一个指定初始容量 和 负载因子 的具有指定迭代顺序的LinkedHashMap
初始容量 和 负载因子是影响HashMap 性能的两个重要参数。同样地,它们也是影响LinkedHashMap 性能的两个重要参数。此外,LinkedHashMap 增加了双向链表头结点,和标志位 accessOrder 两个属性用于保证迭代顺序。
1.3.2、LinkedHahsMap(Map<? extends K,? extends V> m)
该构造函数意在构造一个与指定 Map 具有相同映射的 LinkedHashMap,其初始容量不小于 16(具体依赖于指定 Map 的大小),负载因子是 0.75,是 Java Collection Framework 规范推荐提供
1 | public LinkedHashMap(Map<? extends K, ? extends V> m) { |
1.4、LinkedHashMap 的数据解构
本质上,LinkedHashMap = HashMap + 双向链表,也就是说,HashMap 和双向 链表合二为一即是 LinkedHashMap。也可以这样理解,LinkedHashMap 在不对 HashMap 做任何改变的基础上,给 HashMap 的任意两个节点加了两条连线(before指针 和 after指针),使这些节点形成一个双向链表。
在LinkedHashMap 中, 所有put 进来的Entry 都保存在 HashMap 中, 但由于它有额外定义了一个以head 为头结点的空的双向链表,因此对于每次put进来的Entry 还会将其插入到双向链表的尾部。
1.5、put 和 get 操作
1.5.1、put 操作
LinkedHashMap 没有 put 方法,插入操作交给了HashMap,通过重写 newNode、newTreeNode方法来创建自己的节点,并对 before 与 after 进行操作。
1 | // 重写 newNode 方法 |
在LinkedHashMap 中,添加节点是通过 HashMap 的put 方法来添加,当创建新的节点时,调用的方法为 LinkedHashMap的 newNode、newTreeNode 。从 linkNodeLast 可以看出,无论是插入顺序还是LRU 顺序,新插入的节点都讲被放在末尾。在 HashMap 的 putVal 方法末尾有这两个判断:
1 | if (e != null) { // existing mapping for key |
第一行代码:如果e 不为 null,代表 key 重复,新的value 值替换旧值,afterNodeAccess(e)被调用,该方法在 HashMap 中为空,在 LinkedHashMap 实现,作用就是对 asccessOrder 为 true 情况(LRU顺序)下将该节点调到末尾,因为它被改动了。
在afterNodeAccess 方法中,将 e 节点的前一个节点 b 与后一个节点 a 连在一起,将 e 调到末尾。LRU 顺序下,末尾节点代表着最新的节点,意思是要么是:新插的,被更改的、被 get 访问到的。
第二段代码:插入新节点后,对于 LinkedHashMap 来说要进行 afterNodeInsertion 操作,作用是判断是否是要删除 head 节点,这是一个拓展点,可以重写 removeEldestEntry 方法,执行自己的逻辑,比如数量超过某值后插入新值会删除最久未被操作的值,即头结点。
1 | void afterNodeInsertion(boolean evict) { // possibly remove eldest |
关于 evict ,默认是 true。在 HashMap 的put 方法中,调用 putVal 传的是 true,那么决定是否删除 head 节点的操作就取决于 removeEldestEntry 方法。
1.5.2、get 操作
LinkedHashMap 的 get 操作是调用自身的 get 方法,重写了 HashMap 的 get 方法。而其中的具体实现调用了 HashMap 的 getNode 方法。getNode 后,可以看到如果是 LRU 顺序,则被访问的节点会被移到末尾。
1 | public V get(Object key) { |
1.5.3、remove操作
remove 具体操作仍然是在 HashMap 里实现,同 putVal 一样,留下一个钩子
1 | final Node<K,V> removeNode(int hash, Object key, Object value, |
1.5.3、迭代器
afterNodeRemoval 方法就是将该节点的前后连在一起,链表的删除操作。
二、LinkedHashMap 与 Lru
heade 是LinkedHashMap 所维护的双向链表的头结点,而 accessOrder 用于决定具体的迭代顺序。实际上,accessOrder 标志位的作用不像我们描述这样简单。
当 accessOrder 标志位位 true 时, 表示双向链表中的元素按照访问的先后顺序排列,可以看到,虽然Entry 插入链表的顺序依然是按照其 put 到 LinkedHashMap 中的顺序,但 put 和 get 方法均有调用 afterNodeAccess 方法。
afterNodeAccess 方法判断 accessOrder 是否为 true,如果是,则将当前访问的 Entry 移到双向链表的尾部;
当标志位 accessOrder 的值为 false 时, 表示双向链表中的元素按照 Entry 插入 LinkedHashMap 中的先后顺序排序,即每次 put 到 LinkedHashMap 中的 Entry 都放在双向链表的尾部,这样遍历双向链表时, Entry 的输出顺序和插入的顺序一致,这也是默认的双向链表的存储顺序。
三、总结
LinkedHashMap 将具体操作都交给了 HashMap,二者直接究竟是如何配合的?
这涉及到 LinkedHashMap 如何利用 HashMap 来实现直接的功能,是这样的,在 HashMap 的插入删除等操后会调用钩子方法(afterNodeAccess,afterNodeInsertion,afterNodeRemoval),而这些方法的实现就在 LinkedHashMap 中,这些方法的目的就是操作 before 和 after 指针。LinkedHashMap 重写 newNode,newTreeNode 方法,这两个方法是在插入时 HashMap 构建新节点时调用的,对于重写后 newNode 先是创建 HashMap 的 TreeNode 节点,因为其继承自 LinkedHashMap#Entry,所以含有 before/after 指针,之后同样加入到链尾。
在分析HashMap源码时,发现static final class TreeNode<K,V> extends LinkedHashMap.Entry<K,V>,为什么不直接继承Node,而且在相关方法中也没有用到Entry的before与after指针?
若是TreeNode 直接继承自 Node,那么对于 LinkedHashMap#Entry 就要继承自 TreeNode,那么对于 LinkedHashMap 来说它的每个节点都将含有 left、right、parent、prev 四个指针,就是没必要的,浪费空间。所以采用 TreeNode 继承 LinkedHashMap.Entry 的方式,当然对于 HashMap,它没有任何关于 before/after 的操作,对于它来说这是种浪费,但相比较而言采用这种方式更好。而且,对于 HashMap 来说若 key 的 hashCode 方法实现的够好的话,指的是分布均匀,那么树将很少出现。
四、Android 的 LruCache
1 | public final V put(K key, V value) { |
在 Android 的 LruCache 源码中 put 方法负责将 key 和 value 添加到 LinkedHashMap 中,同时更新 size 记录缓数据的大小。最后调用 trimToSize 让已缓存大小小于等于最大缓存大小,会移除最近最少使用的缓存数据。每次put 的时候,都去检查。当 LruCache 达到最大缓存值时,以后put 都有有可能执行删除操作。
五、Glide LruCache
1 |
|
在 Glide 的 LruCache 中,put 方法的作用就是把 key 和 value 放到 LinkedHashMap 中,同时要更新 LruCache 维护的已缓存大小(Android LruCache 是 size 字段, Glide LruCache 是 currenSize 字段),具体而言就是加上value 的大小减去 previous 的大小。最后,通过 trimToSize 去检查缓存有没有超限。
资料来源:
https://blog.csdn.net/zhongyili_sohu/article/details/105969763
https://www.cnblogs.com/AliCoder/p/11815353.html
https://blog.csdn.net/sinat_34976604/article/details/80971616