HashMap 的底层数据结构:散列表 + 红黑树。关于散列表,采用拉链法处理hash冲突,其中通过引入红黑树来提升效率。
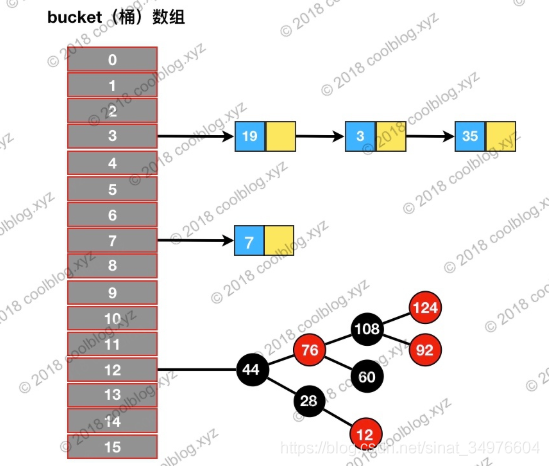
数组+链表+红黑树
图中是一个 Node数组 transient Node<K,V>[] table ; 每个黑点就是一个 Node
Node.hash 是 key 的 hash
1.8 的 HashMap 增加了红黑树来加强存取效率,红黑树的节点
TreeNode
1 | static final class TreeNode<K,N> extends LinkedHashMap.Entry<K,V> |
这样是方便了红黑树与链表之间的转换。
关于 Hash,数组容量
HashMap 有四个构造器,下面只挑取其中的两个来分析。
1 | public HashMap() { |
数组初始大小16,阀值12
1 | public HashMap(int initialCapacity) { |
构造函数中并没有初始化数组大小,而是先设置阀值 threshold, tableSzieFor 方法会返回大于等于传入值的最小2的指数。如传入 5 ,返回 $2^3$。那么什么时候会初始化数组 table 的大小?在第一次调用 put 时,在 putVal 中调用 resize 方法,在该方法中绘制阀值不为零而数组未初始化的情况下将数组大小设为阀值大小。
HasnMap 的hash 算法本质上是三步:取key 的hashCode 值、高位运算、取模运算。
key 的 hash 计算
1 | static final int hash(Object key) { |
为什么 hashcode 还要异或运算?
^ 异或运算:相同置0,不同置1
2
3
4
5
1^1 = 0
1^0 = 1
0^0 = 0
0和1 的概率都为 1/2在 jdk1.7 中有
indexFor(int h, int length)方法,jdk1.8 里没有,但原理一样,与jdk1.8中用tab[(n - 1) & hash]代替但原理一样
2
3
return h & (length-1);
}这个方法返回值就是数组下标。我们平时用map大多数情况下map里面的数据不是很多。这里与(length-1)相&,
但由于绝大多数情况下length一般都小于2^16即小于65536。所以return h & (length-1);结果始终是h的低16位与(length-1)进行&运算。如下例子(hashcode为四字节)
例如1:为了方便验证,假设length为8。HashMap的默认初始容量为16
length = 8; (length-1) = 7;转换二进制为111;
假设一个key的 hashcode = 78897121 转换二进制:100101100111101111111100001,与(length-1)& 运算如下
2
3
4
5
6
7
&运算
0000 0000 0000 0000 0000 0000 0000 0111
= 0000 0000 0000 0000 0000 0000 0000 0001 (就是十进制1,所以下标为1)上述运算实质是:001 与 111 & 运算。也就是哈希值的低三位与length与运算。如果让哈希值的低三位更加随机,那么&结果就更加随机,如何让哈希值的低三位更加随机,那么就是让其与高位异或。
补充知识:
当length=8时 下标运算结果取决于哈希值的低三位
当length=16时 下标运算结果取决于哈希值的低四位
当length=32时 下标运算结果取决于哈希值的低五位
当length=2的N次方, 下标运算结果取决于哈希值的低N位。
原因总结:
由于和(length-1)运算,length 绝大多数情况小于2的16次方。所以始终是hashcode 的低16位(甚至更低)参与运算。要是高16位也参与运算,会让得到的下标更加散列。
所以这样高16位是用不到的,如何让高16也参与运算呢。所以才有hash(Object key)方法。让他的hashCode()和自己的高16位^运算。所以(h >>> 16)得到他的高16位与hashCode()进行^运算。
因为大部分情况下,都是低16位参与运算,高16位可以减少hash冲突
key 在 table[]中位置计算
1 | (n - 1) & hash |
为什么 数组大小一定是2的指数?
让大小是 2^n,是为了对取模运算进行优化,& 比 % 具有更高的效率,当length 总是 2^n 时,h&(length-1) 运算等价于对 length 取模,也就是 h%length。
扩容机制
在 resize() 方法中,当数组超过阀值 threshold 时,会重新计算阀值 threshold = capacity * loadFactor 扩容。
从代码中可以看出,resize 方法不仅承担了扩容功能,还有初始化数组大小的功能。
- 如果
oldCap>0,将数组大小扩大两倍,阀值同样扩大两倍 - 如果
oldCap == 0 && oldThr > 0,比如调用了规定容量大小的构造函数。将容量设为阀值大小。 - 如果
oldCap == 0,代表初始化操作,数组大小为16,阀值为12。
接下来如果 oldTab!=null 代表是扩容操作,对节点重新定位,一个节点 Node 的 hash 字段指的是 key 的hash,在确定它在数组中的位置是在putVal 方法中,采用的是 hash & (capacity-1),capacity 能取什么值?2的指数倍数。在重新安排新位置时先遍历数组,针对每个 node,将里面的节点按照 hash & capacity 分为两拨,一拨(hash & capacity==0) 放在旧位置处,另一拨放在 oldCap+ 旧位置 = 新位置处。
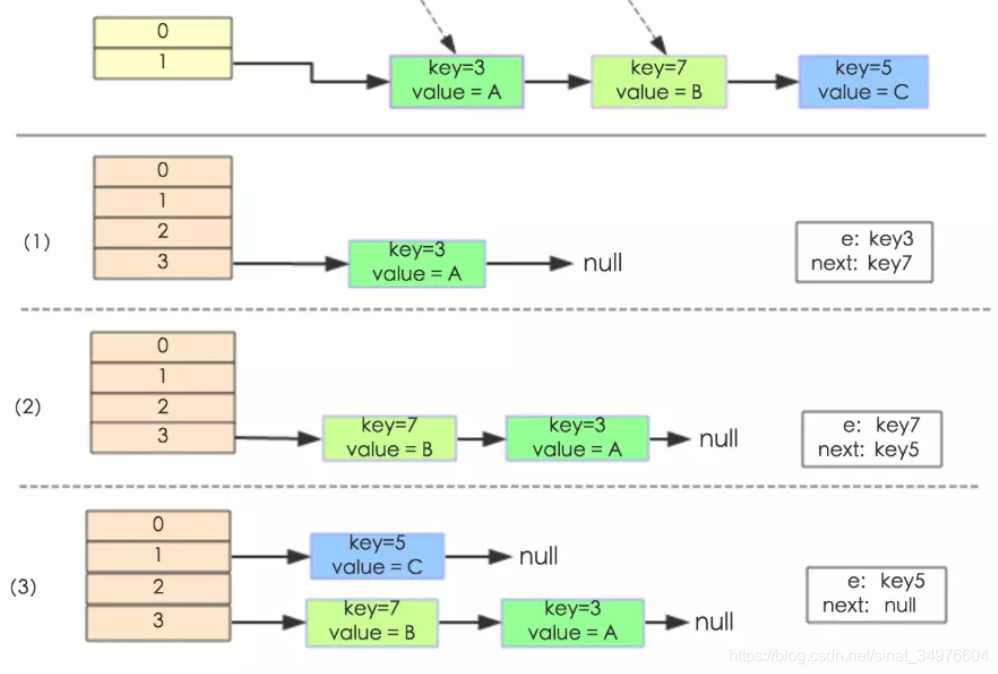
如下图:是jdk1.7 的 HashMap 的扩容操作,与1.8 不同的是重新定位后节点在链表中原先的先后顺序会倒过来,即如图中 3与7 在新位置处的顺序倒了,而这会导致在并发下出现死循环问题,1.8对此做了更改,维持原有顺序不动,即一条链上的节点重新hash 后保持原链中的前后顺序
扩容后数组变为原来的两倍,那么一个节点的 hash & (capacity-1) 的值要么等于原来,要么移动2的幂次方。其中对上面这两种情况的判断语句:(e.hash & oldCap)==0
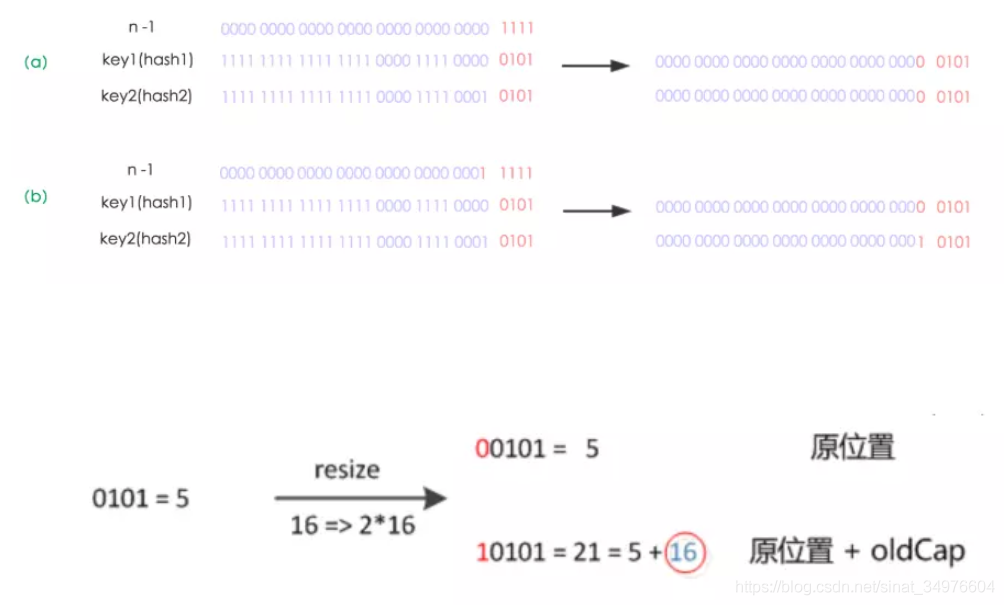
这个设计确实非常巧妙,既省去了重新计算hash值的时间,同时,由于新增的 1bit 是0还是1可以认为是随机的,因此resize 的过程,均匀的把之前的冲突的节点分散到新的 butcket
其中 TreeNode 的 split 方法,同链表处理相同,仍分为两拨,分法也一样,这里当其中一方节点数 <= 6,则恢复成链表;否则重新树化 treeify。
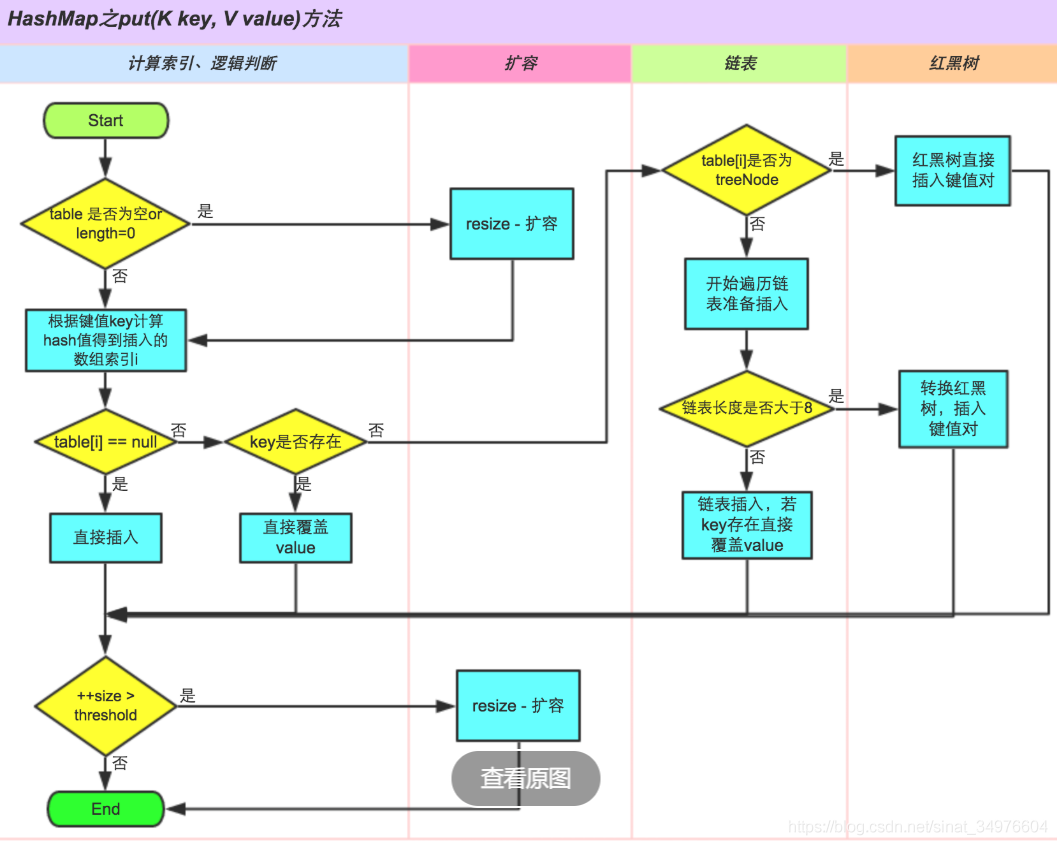
HashMap 的put
putVal 的逻辑很清晰,如果key 存在onlyIfAbsent 为 false 表示更新 value 值,至于 afterNodeAccess 与 afterNodeInsertion 与这两个钩子方法是留给 LinkedHahsMap 的。put 的流程图如下:
树化调用的方法是 treeifyBin
1 | /** |
当数组大小 <64 时,执行扩容操作。即当某个 node 的节点个数大于8, 但数组大小 < 64,进行扩容而不是树化。
关于 HashMap 的死循环
1.7 的HashMap 在多线程下 resize 是会出现死循环,导致 cpu100%,原因是1.7的 resize 会将原先节点的顺序倒过来。死循环问题的定位一般都是通过 jps + jstack 查看堆栈信息来定位的。
1.8 扩容时保持了原来链表中的顺序,避免了这个问题。
HashMap 的 table 为什么是 transient 的?
transient Entry[] table;也就是说 table 里面的内容不会被序列化,为什么?对 HashMap 来说 hashcode 至关重要,而 Object 里的hashcode 是native 方法
public native int hashCode()。这意味着:HashCode 和底层实现相关,不同的虚拟机有可能有不同的 HashCode 算法。Java 的优势跨平台性,如果不用 transient 修饰 table,那么便会失去这一特性。
JDK1.8HashMap 数据覆盖问题
jdk1.8 HashMap 操作源码:
1 | final V putVal(int hash, K key, V value, boolean onlyIfAbsent, |
在 jdk1.8 中 HashMap 中的put 操作函数,在代码第6,7行,如果hash 碰撞则会直接插入元素。这样就会有一个问题。
如果在线程 A 和线程 B 同时进行 put 操作,刚好这两条不同的数据 hash 值一样,并且该位置数据为null,所以线程 A 、B 都会进入第6行代码中。假设,线程 A 进入后还没有进行数据插入时挂起,而线程B 正常执行,从而线程A获取CPU 时间片,此时线程A 不用再进行hash判断,问题出现:线程A 会把线程B插入的数据给覆盖,发生线程不安全。
总结
HashMap 是线程不安全的,主要体现在:
- 在jdk1.7中,在多线程环境下,扩容是会造成环形链或数据丢失
- 在 jdk 1.8 中,在多线程环境下,会发生数据覆盖的情况。
资料来源:
https://mp.weixin.qq.com/s/VtIpj-uuxFj5Bf6TmTJMTw
https://blog.csdn.net/sinat_34976604/article/details/80970981