一、Java 的I/O演进之路
Java1.4之前的早期版本,对I/O的支持并不完善,使得开发人员在开发高性能I/O程序时,面了巨大的挑战和困难,其主要问题如下:
- 没有数据缓冲区,I/O 性能存在问题;
- 没有C或者C++中的Channel概念,只有输入和输出流;
- 同步阻塞式 I/O 通信(BIO),通常会导致通信线程被长时间阻塞;
- 支持的字符集有限,硬件可移植不好。
I/O 基础入门
Linux 网络 I/O 模型简介:
Unix 网络编程对I/O 模型的分类,提供了5种I/O模型,分别如下:
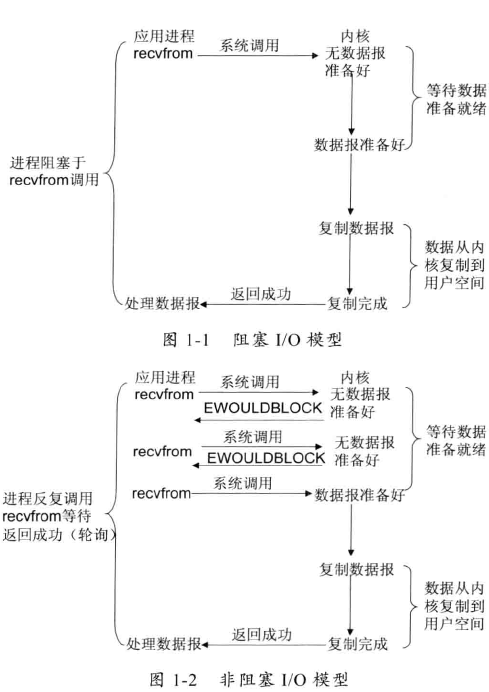
- 阻塞I/O模型
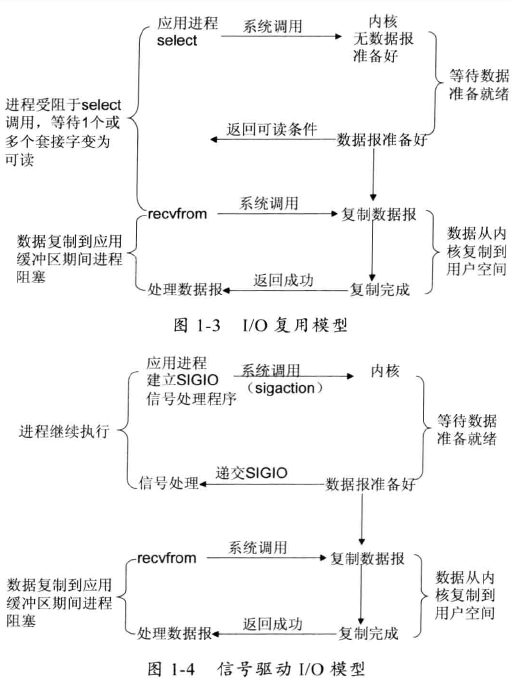
- 非阻塞I/O模型
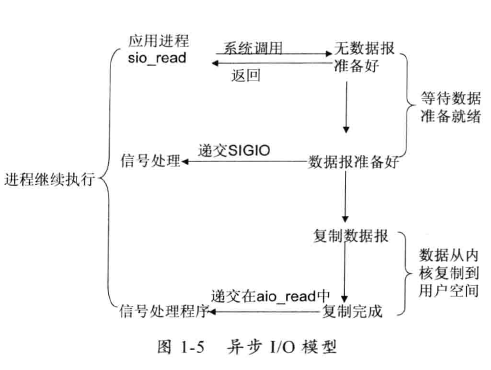
- I/O 复用模型
- 信号驱动 I/O 模型
- 异步 I/O
I/O多路复用
I/O多路复用技术通过把多个 I/O 的阻塞复用到同一个select 的阻塞上,使得系统在单线程的情况下可以同时处理多个客户端请求。与多线程或多进程模型比,I/O 多路复用降低了系统开销,节省系统资源。应用场景如下:
- 服务器需要同时处理多个处于监听状态或者多个连接状态的套接字;
- 服务器需要同时处理多种网络协议套接字。
目前之前的 I/O 多路复用的系统调用有:select、pselect、poll、epoll
Java 的 I/O 演进
在 Java 1.4 推出 Java NIO 之前,基于Java 的所有Socket 通信都采用了同步阻塞模式(BIO),这种一请求一应答的同学模型简化了上层的应用开发,但性能和可靠性却存在巨大的瓶颈。
从 JDK1.0 到 JDK1.3 ,只有 BIO
JDK1.4 新增 java.nio 包,提供很多进行异步 I/O 开发的类库和 API,主要类和接口:
进行异步I/O操作的缓冲区 ByteBuffer 等;
进行异步I/O操作的管道 Pipe;
进行各种 I/O 操作(异步or同步)的Channel,包括 ServerSocketChannel 和 SocketChannel;
多种字符集的编解码能力;
实现非阻塞 I/O 操作的多路复用器 selector;
基于流行的 Perl 实现的正则表达式类库;
文件通道 FileChannel。
它的不足有:没有统一的文件属性(例如读写权限)
API 能力比较弱,如目录的级联创建何递归遍历,往往需要自己实现
底层存储系统的一个些高级API无法使用
所有文件操作都是同步阻塞调用,不支持异步文件读写
JDK1.7 对原有的 NIO库进行了升级,被称为 NIO2.0,主要改进有:
- 提供能够批量获取文件属性的API,这些API具有与平台无关性,不与特性文件系统相耦合
- 提供 AIO 功能,支持基于文件的异步 I/O 操作和针对网络套接字的异步操作
- 完成 JSR-51定义的通道功能,包括对配置和多播数据包的支持等。
二、NIO入门
传统的BIO编程
网络编程的基本模型是 Client/Server 模型,也就是两个进程之间进行相互通信,其中服务端提供位置信息(IP地址和监听端口),客户端通过连接操作服务端监听地址发起连接请求,通过三次握手建立连接,如果连接成功,双方就可以通过套接字(Socket)进行通信。
在传统的 BIO 编程中,ServerSocket 负责绑定 IP地址,启动监听端口;Socket 负责发起连接操作,连接成功后,双方通过输入流和输出流进行同步阻塞式通信。
BIO 通信模型图
采用 BIO 通信模型的服务端,通常由一个独立的 Acceptor 线程负责监听客户端的连接,收到客户端的连接请求后为每个客户端创建一个新的线程进行链路处理,处理完成后,通过输出流返回应答给客户端,线程销毁。
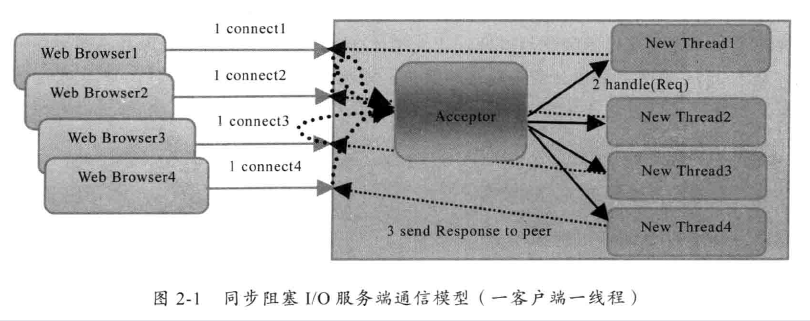
该模型最大的问题是缺乏弹性伸缩能力,当客户端的访问数量增加时,服务端的线程数和客户端并发访问数呈现1:1的正比例关系,由于线程是虚拟机非常宝贵的系统资源,当线程数量膨胀后,系统性能将会急剧下降,随着并发访问量的继续增大,系统会发生线程堆栈溢出,创建新线程失败等问题,导致进程宕机僵死,无法提供对外服务。
同步阻塞式 I/O 创建的TimeServer 源码分析
1 | public class TimeServer { |
程序中通过ServerSocket 监听指定端口,如果没有被占用,服务端监听成功。如果没有客户端接入,则主线程阻塞在 accept() 操作上,直到有新的客户短连接进来。
同步阻塞式 I/O 创建的 TimeClient 源码分析
1 | public class TimeClient { |
客户端通过 Socket 连接到服务端,通过 PrintWriter 向服务端发送 QUERY_TIME_ORDER 指令,然后通过 BufferReader 读取服务端响应结果。
BIO主要问题是当有新的客户端请求接入时,服务端需要创建一个新的线程处理新接入的客户端链路,一个线程只能处理一个客户端连接,在高性能服务器应用领域,往往需要成千上万个客户端的并发连接,无法满足高性能,高并发的接入场景。
伪异步 I/O 编程
为解决同步阻塞 **I/O ** 面临的一个链路需要一个线程处理的问题,后来有人通过对线程模型的优化——后端通过线程池来处理多个客户端的接入请求,形成客户端M,线程池最大线程数 N 的比例关系,M远大于N,通过线程池灵活地调配资源,设置线程最大值,防止海量并发接入导致资源耗尽。
伪异步 I/O 模型图
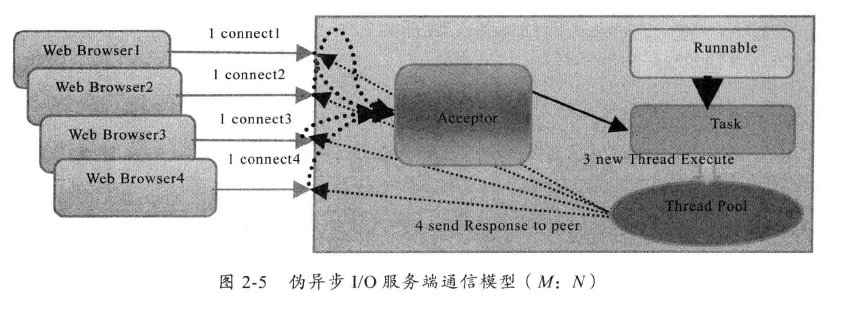
当有新的客户端接入时,将客户端 Socket 封装成一个 Task (实现 Runnable 接口)投递到后端线程池中进行处理,线程池维护一个消息队列和 N 个活跃线程,对消息队列中的任务进行处理。
伪异步 I/O 创建的TimeServer 源码分析
1 | public class AnycBioTimeServer { |
线程池和消息队列类都有界,无论客户端并发连接数量多大,都不会导致线程个数膨胀或者内存溢出。采用线程池实现,避免了并发连接请求对系统资源的消耗问题。但是底层依然是同步阻塞模型,无法从根本上解决问题。
伪异步 I/O 的弊端
读写(read、out)操作都是同步阻塞,阻塞时间取决于对方 I/O 线程处理速度和网络 I/O 的传输速度。
线程池阻塞队列积满后,后续入队列操作将被阻塞。
NIO 编程
相比于BIO 的 ServerSocket 和 Socket ,NIO 提供了ServerSocketChannel 和 SocketChannel 两种不同的套接字通道实现。新增的通道都支持 阻塞式 和 非阻塞式 两种模式。一般来说,低负载、低并发的应用程序可以选择同步阻塞I/O以降低编程复杂度;对于高负载,高并发的网络应用需要使用NIO模式进行开发
NIO 类库简介
NIO 库是 JDK1.4 中引入的,弥补了原来 BIO 同步阻塞的不足,在标准的 Java 代码中提供了高速的、面向块的 I/O,通过定义包含数据的类,以及通过以块的形式去处理这些数据,NIO 不使用本机代码就可以利用低级优化,这是原来 I/O 包所无法做到的。
缓冲区 Buffer
Buffer 是一个对象,它包含要读出或者写入的数据,在 NIO 库中加入 Buffer对象,体现新库与原来 I/O 库的一个重要区别。在面向流的 I/O 库中,可以将数据直接读入或者写出到 Stream 对象中。
在 NIO 库中,所有数据都是用缓冲区处理的。在读取数据时,直接读到缓冲区中;同样,写数据时,写入到缓冲区中。任何访问 NIO中的数据,都是通过缓冲区进行操作。
缓冲区实质是一个数组。通常它是一个字节数组(ByteBuffer),也可以使用其他种类数组,缓冲区不仅仅是一个数组,还提供了对数据结构化访问以及维护读写位置(limit) 等信息。
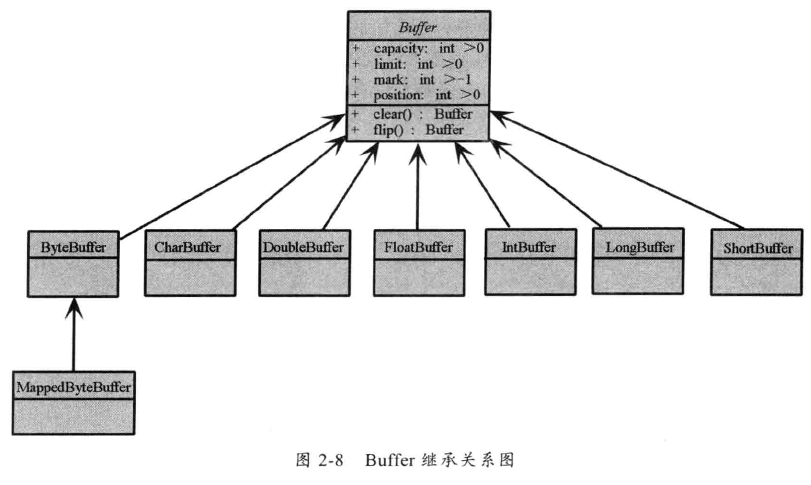
每个 Buffer 类都是 Buffer 接口的一个子实例,除了 ByteBuffer, 每一个 Buffer 类都有完全一样的操作,只是它们所处理的数据类型不一样。因为大多数标准 I/O 操作都使用ByteBuffer,所以它具有一般缓冲区操作之外还提供了一些特有的操作,以便网络读写。
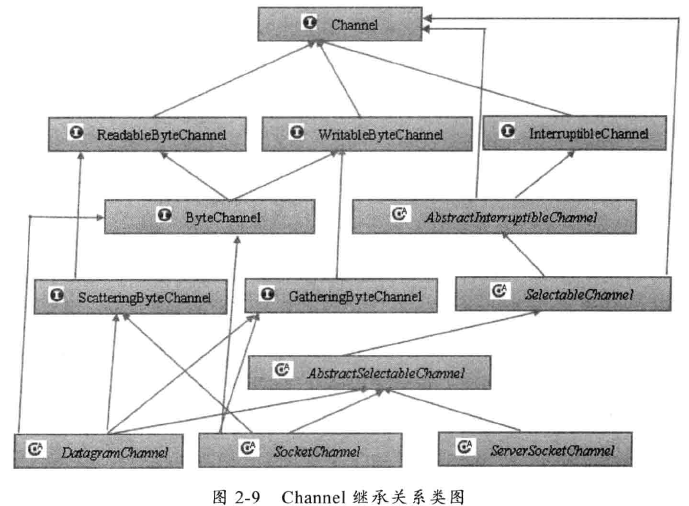
通道Channel
Channel 是一个通道,像自来水管一样,网络数据通过 Channel 读取和写入。通道与流的不同之处在于通道是双向的,流只在一个方向移动(一个流必须是 InputStream 或者 OutputStream),而通道可以用于读、写同时进行。
因为 Channel 是全双工,所以比流更好的映射底层操作系统API。
多路复用器
多路复用器 Selector , 是Java NIO 编程基础,它提供已经选择就绪的任务的能力。简单来讲,Selector 会不断轮询已经注册在其上的 Channel,如果 Channel 发生读写事件,这个Channel 就处于就绪状态,会被 Selector 轮询出来,然后通过 SelectionKey 可以获取就绪 Channel 集合,进行后续的 I/O 操作。
一个多路复用器可以同时轮询多 Channel,由于 JDK 使用了 epoll() 代替传统的 select 实现,所以他并没有最大连接句柄 1024/2048 的限制。这也意味着只需要一个线程负责 Selector 的轮询,就可以接入成千上万的客户端。
NIO 服务端序列图
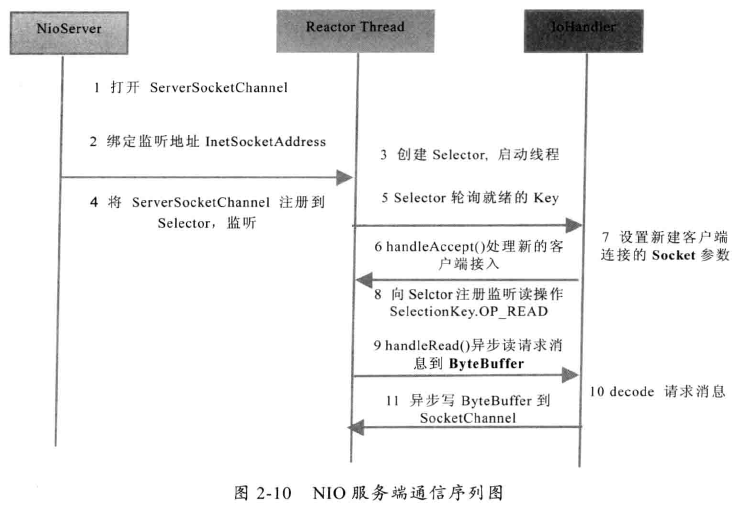
NIO 创建的 TimeServer 源码分析
1 | public class NIOTimeServer { |
初始化资源,创建多路复用器
Selector、ServerSocketChannel,对 Channel 和 TCP 参数进行配置。如:将 ServerSocketChannel 设置为异步非阻塞,backlog = 1024。将 ServerSocketChannel 注册到 Selector,监听 SelectionKey.OP_ACCEPT 操作位。在 run 方法体中循环遍历 selector ,它的休眠时间为 1s ,不管是否有读写事件发生,selector 每隔 1s都会被唤醒一次,selector 提供无参方法 selectedKeys,当有处于就绪状态的 Channel 时,selector 将返回该 Channel 的 SelectionKey 集合
在处理新接入客户端消息时,根据 SelectionKey 操作位判断可获知网络事件类型,通过 ServerSocketChannel 的 accept 接收客户端的连接请求,并创建 SocketChannel 实例 ,完成上述步骤相当于完成 TCP 三次握手,TCP 物理链路正式建立。
读取客户端消息时,先创建一个ByteBuffer ,由于事先不知客户端发送的码流的大小,在例程中,开辟 1MB 大小的缓冲区。接着调用SocketChannel 的 read 方法读取码流,因设置SocketChannel 为异步非阻塞模式,因此 read 也是非阻塞的。读取到码流后,进行解码。首先对 Byteffer 进行 flip() 操作,它的作用是将缓冲区当前的 limit 设为 position,position设置为0,用于后续对缓冲区的操作。然后根据缓冲区的可读字节个数创建字节数组,调用Byteffer的get 方法,将缓冲区中可读的字节数据复制到新创建的字节数组。
读取到数据的字节数可能有以下几种情况
- 返回值大于0:读到了字节,对字节数据编解码
- 返回值等于0:没有读到字节,属于正常情况,可忽略
- 返回值小于-1:链路已经关闭,需要关闭 SocketChannel,释放资源。
应答消息发送给客户端时,先将字符串编码成字节数组,根据字节数组的容量创建 ByteBuffer,调用 put 方法将字节数组复制到缓冲区中,然后调用 flip 操作,最后调用 SocketChannel 的 write 方法将缓冲区中的数据发送出去。
NIO 客户端序列图
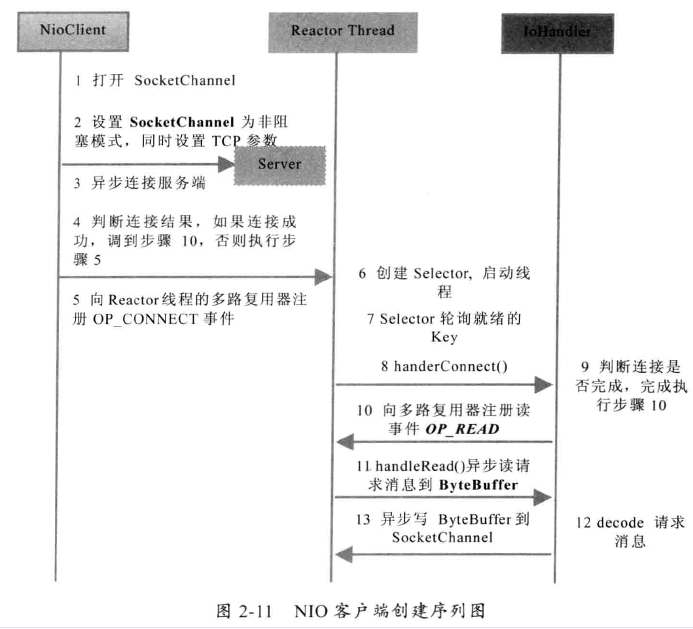
NIO 创建的TimeClient 源码分析
1 | public class NIOTimeClient { |
- 初始化多路复用器
Selector、SocketChannel,创建SocketChannel对象后,将其设置为异步非阻塞模式。 - 对
SocketChannel的 connect 操作进行判断。如果连接成功,则将SocketChannel注册到多路复用器Selector上,注册SelectionKey.OP_READ; 如果没有连接成功,说明服务端没有返回 TCP 握手应答信息,但是不意味着连接失败。需要将SocketChannel注册到多路复用器Selector上,注册SelectionKey.OP_CONNECT,当服务端TCP响应 sync-ack 消息后,Selector就能轮询到这个SocketChannel处于连接就绪。 - 循环体中轮询多路复用器
Selector,当有就绪的 Channel 时,会调用 handlerInput(key) 方法,下面将会分析 - 在上面的代码 handlerInput 方法中,对 SelectionKey 的状态进行判断,如果处于连接状态,说明服务端 TCP 已经响应返回 ACK 应答消息。这时需要调用 SocketChannel 的 finishConnect 方法判断,如果返回 true,说明客户端连接成功;如果false或者抛出 IOException 异常,说明连接失败。在例程中,连接成功后则把 SocketChannel 注册到多路复用器上,注册
SelectionKey.OP_READ操作位,监听网络读操作,然后发送请求消息给服务端。 - 发送消息给服务端是先对消息编码成字节数组,然后写入到数据缓冲区 ByteBuffer,最后调用 SocketChannel 的 write 方法发送到服务端。由于发送是异步的,存在 ”半写包“ 问题。通过
hasRemaining方法可判断缓冲区的消息是否全部发送完成。 - 如果客户端收到服务端的应答消息,可以根据
SelectionKey的isReadable方法判断 SocketChannel 是可读的,因无法事先判断应答码流的大小,我们可以通过ByteBuffer.allocate(1024)预先分配 1MB 大小的缓冲区空间用于读取应答消息,然后调用 SocketChannel 的 read() 方法进行异步读取应答消息。 - 线程退出循环后,我们需要释放连接资源,由于释放多路复用器资源后,JDK底层会释放所有跟此多路复用器相关联的资源,因此我们无需对 Channel、Pipe 等资源进行一一释放。
NIO编程优点总结:
- 客户端发起的连接操作是异步的,可以通过在多路复用器注册
SelectionKey.OP_CONNECT等待后续结果,不需要像之前的客户端那样被同步阻塞。 SocketChannel的读写操作都是异步的,如果没有可读写的数据它是不会同步等待的,直接返回,这样 I/O 通信线程就可以处理其他的链路,不需要同步等待这个链路可用。- 线程模型优化:由于 JDK 的 Selector 在 Linux 等主流操作系统上通过 epoll 实现,它没有连接句柄数的限制(只受操作系统的最大句柄数或者对单进程的句柄数限制),这意味着一个 Selector 可以同时处理成千上万个客户端连接,而且性能不会随着客户端的增加而线性下降。因此,它非常适合做高性能、高负载的网络服务器。
注:JDK1.7 升级了NIO类库,升级后的NIO类库被称作 NIO2.0,Java 正式提供了异步文件I/O操作,同时提供了与UNIX 网络编程事件驱动 I/O 对应的 AIO。
AIO 编程
NIO 2.0 引入了新的异步通道概念,并提供了异步文件通道和异步套接字通道的实现。其异步套接字通道是真正的异步非阻塞I/O。
异步通道提供了以下两种方式获取操作结果。
- 通过
java.util.concurrent.Future类来表示异步操作的结果。 - 在执行异步操作时传入一个
java.nio.channels。
CompletionHandler 接口的实现类作为操作完成的回调。
AIO创建的TimeServer 源码分析
1 | public class AsynTimeServer { |
在例程中是使用独立线程来创建服务端Handler,在实际项目中不需要独立线程创建,因为底层通过JDK的系统回调实现的。
AsynTimeServerHandler在构造方法中,创建一个异步的服务端通道AsynchronousServerSocketChannel,然后调用其bind()方法绑定监听端口,如果端口合法且没有被占用,则绑定成功。在 run 方法中,初始化 CountDownLatch 对象,其作用是完成一组正在执行的操作之前,允许线程一直阻塞(实际运用中不需用到,此次 CountDownLatch 仅作demo示例)。在
doAccept()方法中,用于接收客户端的连接,我们可以传递 CompletionHandler<AsynchronousSocketChannel, ? super A> 的handler 实例接收 accept 操作成功的消息通知。AcceptCompletionHandler中的 completed 方法可以获取到 AsynTimeServerHandler 的成员变量AsynchronousServerSocketChannel,然后调用它的 accept 方法。细心的同学可能会问,为什么在这里会再次调用 accept 方法呢?原因是:调用AsynchronousServerSocketChannel的 accept 方法后,当有新的客户端连接接入后,系统将会回调我们传入的 CompletionHandler 实例的 completed 方法,表示新的客户端已经接入成功。链路建立成功后,通过
AsynchronousSocketChannel的read()方法进行异步操作,其参数如下:- ByteBuffer dst:结束缓冲区,用于从异步Channel 中读取数据包;
- A attachment:异步 Channel 携带的附件,通知回调的时候作为入参使用;
- CompletionHandler<Integer,? super A> ,接收通知回调的业务Handler
在
ReadCompletionHandler的构造方法中,我们可以拿到AsynchronousSocketChannel的实例,主要用来读取半包信息和发送应答。在completed()方法中是读取消息的处理,首先调用 attachment 的flip()方法,为后续读取缓冲区数据做准备。根据缓冲区数据的可读字节数创建 byte 数组,然后根据 byte 数组 new String 创建消息。dowWrite()方法响应给客户端消息时,首先把字符串消息转换成字节数组,然后通过 ByteBuffer 复制到发送缓冲区,然后通过AsynchronousSocketChannel的异步write()方法发送消息。write()方法的参数和read()方法的参数一样。CompletionHandler 的
failed()方法,其作用是当发生异常时,对异常 Throwable 进行判断,根据异常做出相应的逻辑处理,如 I/O 异常则关闭链路,释放资源。
AIO创建的 TimeClient 源码分析
1 | public class AsynTimeClient { |
客户端例程中,通过新建一个线程来创建一个异步时间服务器连接对象,实际项目中无需独立线程来创建异步连接对象的。
在
AsynTimeClientHandler的源码中,在构造方法中创建了AsynchronousSocketChannel对象,在run()方法中,CountDownLatch进行等待,防止异步操作没有执行完成线程就退出。同时 通过AsynchronousSocketChannel对象调用connect方法发起异步操作,根据服务端地址和端口连接服务端,该方法除地址外的另外两个参数:A attachment:
AsynchronousSocketChannel的附件,用于回调通知时作为入参被传递,调用者可以自定义。CompletionHandler<Void, ? super A> handler : 异步操作回调通知接口,由调用者实现。
例程中两个参数都使用了 AsynTimeClientHandler 本身,因为它也实现了 CompletionHandler 接口。
异步连接成功后的方法回调是
completed(),在该方法中我们可以创建请求体消息,把字符串消息编码成字节数组,然后复制到 ByteBuffer ,最后调用AsynchronousSocketChannel的write方法发送到服务端,write()的方法参数与服务端类似,此处就不展开细说。客户端在读取服务端应答的消息时是通过
AsynchronousSocketChannel的read()方法,其方法入参也和服务端一样。
AIO 的线程堆栈
通过打印线程堆栈信息可知,JDK 底层通过线程池 ThreadPoolExecutor 来执行回调通知,异步回调通知由 cun.nio.AsynchronousChannelGroupImpl 实现,通过层层调用,最终回调 com.phei.netty.aio.AsynTimeClientHandler$1.completed 方法,完成回调通知。
名词概念澄清
1、异步阻塞I/O
不少人喜欢把 JDK1.4 提供的NIO模型叫做异步非阻塞 I/O,如果严格按照 UNIX 网络编程模型和 JDK的实现区分,实际上只能被称为非阻塞I/O,不能叫异步非阻塞I/O。在 JDK 1.4和 JDK 1.5 update 10之前的版本,JDK 的 Selector 是基于 select/pull 模型实现,是基于 I/O 复用技术的非阻塞 I/O,在 JDK1.5 update 10 和 Linux core2.6以上版本,Sun 优化了 Selector 的实现,底层使用 epoll 替换了 select/pull ,上层 API 并没有改变,属于 JDK NIO 的性能优化,没有改变 I/O模型,依然是非阻塞 I/O。
直到 JDK 1.7的出现,提供的NIO2.0 新增了异步套接字通道,才真正的实现了异步 I/O ,也叫AIO。
2、多路复用器 Selector
对于Selector,有的人叫多路复用器,有的叫选择器,实质是同一东西的不同叫法。
Java NIO 的实现关键是多路复用 I/O 技术,其核心就是通过 Selector 来轮询注册在其上的 Channel,当发现有一个或者多个Channel 处于就绪状态,就会从阻塞状态返回就绪的Channel 集合,进行 I/O 操作。
3、伪异步 I/O
伪异步I/O 概念来源于实践,在没有 NIO 模型之前,为解决 Tomcat 通信线程同步 I/O 导致业务线程被挂住问题,使用线程池和消息队列来隔离 I/O 线程和业务线程,这样就业务线程不会被 I/O 线程阻塞。
4种 I/O 的对比
为什么不选择原生JAVA 的NIO编程
- NIO 类库和API 复杂,使用麻烦,需要熟练掌握 Selector、ServerSocketChannel、SocketChannel、ByteBuffer 等。
- 需要具备其他额外技能做铺垫,如 Java 多线程编程,因为 NIO 编程涉及到 Rector 模式,需要对多线程和网络编程非常熟悉,才能写出高质量的NIO 程序。
- 可靠性能力补齐,工作量和难度都非常大,如客户端断连和重连、网络闪断、半包读写、失败缓存、网络拥塞和异常码流处理等问题。
- Java NIO 臭名昭著的 epoll bug,它会导致 Selector 空轮询,最终导致 CPU 100%,虽然官方声称 JDK 1.6 版已修复,但在 JDK 1.7依然存在,只是bug 发生的概率降低了。
为什么选择 Netty
Netty的优点如下:
- API 使用简单,开发门槛较低
- 功能强大,预置了多种编解码功能,支持多种主流协议
- 定制能力强,可通过 ChannelHandler 对通信框架进行灵活的扩展。
- 性能高,通过与其他业界的主流 NIO 框架对比,Netty 的综合性能最高。
- 成熟、稳定,Netty 已经修复所有已经发现的 JDK NIO BUG,业务人员无再为 NIO 的 BUG 而烦恼。
- 社区活跃,版本迭代周期短,发现BUG 可以及时修复,同时更多的新功能会被加入。
- 经历了大规模的商业应用考验,质量得到验证。
三、Netty 入门应用
3.1、Netty 时间服务器服务端
1 | public class NettyTimeServer { |
Netty 创建服务端的步骤主要分为以下几个:
- 通过
NioEventLoopGroup创建EventLoopGroup线程组实例,它包含了一组NIO线程组,专门用于网络事件的处理,实际上就是Reactor线程组。创建两个的原因是:一个用于服务端接收客户端的连接,另一个用于SocketChannel网络读写。 - 创建
ServerBootStrap对象,其作用是启动 NIO 服务端的辅助启动类,目的是降低服务端的开发复杂度。通过它可以设置EventLoopGroup线程组,配置TCP 参数,设置创建channl 为NioServerSocketChannel类,最后绑定 I/O 事件处理类ChildChannelHandler,主要用于处理网络 I/O 事件处理,如记录日志,消息编解码等。 - 配置完成后,通过
ServerBootStrap的实例调用bind()方法绑定监听端口,接着,调用同步阻塞方法sync()等待绑定操作完成。最后会返回一个ChannelFuture的实例,类似于java.util.concurrent.Future,用于异步操作的回调通知。 - 调用
future.channel().closeFuture().sync()方法进行阻塞是为了等待服务端链路关闭后才退出main 函数。 - 在 finally 中关闭 EventLoopGroup 线程组释放资源。
TimeServerHandler继承自ChannelHandlerAdapter,用于对网络事件进行读写操作。关键方法是channelRead、channelReadComplete、exceptionCaught- channelRead 方法主要是接收客户端消息,其有两个入参,一个
ChannelHandlerContext,可以通过其 write 方法异步发送消息响应给客户端;而另一 Object 类型的msg 参数则为接收到的请求信息,可以被转换为 ByteBuf ,ByteBuf 类似于 JDK 中的 ByteBuffer ,不过它提供了更加灵活和强大的功能。可以公共 ByteBuf 的 readableBytes 获取缓冲区中的可读字节数。 - channelReadComplete 方法中,调用了 ChannelHandlerContext 的 flush 方法,其作用是将消息发送队列中的消息写入到
SocketChannel中发送给对方。从性能角度考虑,为了防止频繁地唤醒 Selector 进行消息发送,Netty 的 write 方法并不直接将消息写入到 SocketChannel 中,调用 write 方法只是把待发送的消息放到发送缓冲数组中,再通过调用flush 方法,将缓冲区中的消息全部写入到 SocketChannel 中。 - exceptionCaught 是异常处理方法,出现异常是通过调用 ChannelHandlerContext 的 close 方法及时关闭释放资源。
- channelRead 方法主要是接收客户端消息,其有两个入参,一个
3.2、Netty 时间服务器客户端
1 | public class NettyTimeClient { |
比起创建服务端,创建Netty 客户端更加简单
- 在connect 方法中,首先通过
NioEventLoopGroup创建EventLoopGroup的实例,处理客户端的网络 I/O 线程组,然后创建客户端的辅助启动类Bootstrap的实例并进行配置。客户端使用的 Channel 为NioSocketChannel,最后添加绑定 ChannelHandler 处理网络 I/O 事件。 TimeClientHandler中有三个重要的方法,分别为:channelActive、channelReadComplete、exceptionCaught,后两个就不展开说了,与上面的服务端相似,主要说下channelActive方法,该方法主要是在客户端与服务端TCP 通信链路建立后,Netty 的 NIO 线程会调用该方法。
四、TCP 粘包/拆包问题的解决之道
4.1、TCP 粘包/拆包
TCP 是个 “流” 协议,所谓流,就是没有界限的一串数据。TCP 并不了解上层业务数据的具体含义,它会根据缓冲区的实际情况进行包的划分,所以在业务上任务,一个完整的包可能会被拆分成多个包进行发送,也有可能把多个小的包封装成一个大的数据包发送,这就是所谓的 TCP 粘包和拆包问题。
4.1.1 TCP 粘包/拆包问题说明
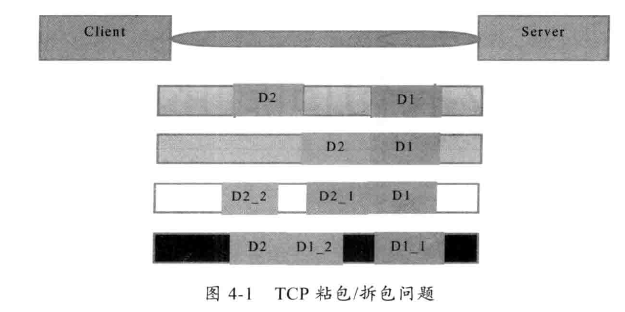
假设客户端分别发送了两个数据包 D1 和 D2 个服务端,由于服务端一次读到的字节数是不确定的,可能存在以下 4 种情况。
- 服务端分两次读取到了两个独立的数据包,分别是 D1 和 D2,没有发生粘包和拆包问题。
- 服务端一次读到了两个数据包,D1 和 D2 粘在一起,被称为 TCP 粘包。
- 服务端分两次读到了两个数据包,第一次读取到了完整的 D1 包和 D2 包的部分内容,第二次读到了 D2 包的剩余内容,这被称为 TCP 拆包。
- 服务端分两次读到了两个数据包,第一次读取到 D1包的部分内容,第二次读到了 D1包剩余的内容以及完整的D2 包内容。
如果服务端 TCP 接收滑窗非常小,而数据包 D1 和 D2 比较大,有可能会发生第5种情况,服务端要分多次才能将 D1 和 D 包完全接收,期间发生多次拆包。
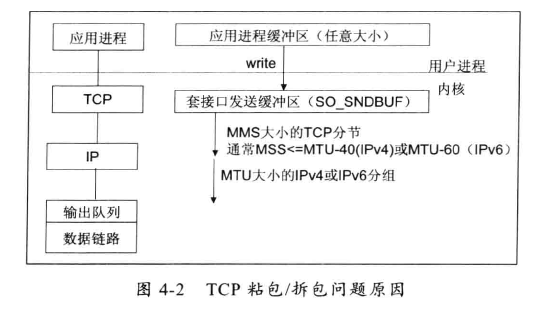
4.1.2、TCP 粘包拆包发生的原因
- 应用程序 write 写入的字节大小大于套接口发送缓冲区大小;
- 进行MSS大小的 TCP 分段;
- 以太网帧的 payload 大于 MTU 进行 IP 分片。
4.1.3、粘包问题的解决策略
由于底层 TCP 无法理解上层的业务数据,所以在底层无法保证数据包不被拆分和重组,这个问题只能通过上层的应用协议栈设计来解决,主流协议的解决方案如下:
- 消息定长,如每个报文的大小固定为200个字节,如果不够,空位补空格;
- 在包尾增加回车换行进行分割,如 FTP 协议;
- 将消息分为消息头和消息体,消息头包含表示消息总长度(或者消息体的长度)的字段,通常设计思路为消息头的第一个字段使用 int32 来表示消息的总长度;
- 更为复杂的应用层协议。
4.2、未考虑 TCP 粘包导致功能异常的案例
通过模拟故障场景,然后看看如何正确使用 Netty 半包解码器来解决 TCP 的粘包和拆包问题。
4.2.1、NettyTimeServer改造
1 | public class MonitorTimeServerHandler extends ChannelHandlerAdapter { |
对服务端的改造是,增加一个全局 int counter 变量,每接收到一次消息就计数一次,然后发送应答给客户端。按设计服务端收到的消息数与客户端发送的消息数应该保持一致。
4.2.2、NettyTimeClient 改造
1 | public class MonitorTimeClientHandler extends ChannelHandlerAdapter { |
对客户端的改造是,建立连接后,循环发送消息100次,每发送一条消息就刷新一次,保证每条消息都被写入到Channel 中,按设计服务端应该收到客户端的100条查询指令。同时增加一个全局的 countor,每收到一次服务端的应答消息就计数一次,同样地,应该是打印100 次服务端响应的时间消息。
4.2.3、运行结果
服务端运行结果如下
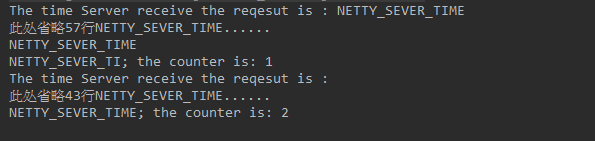
从服务端的运行结果可以看到,服务端总共只收到两条消息,第一条包含了57条 NETTY_SERVER_TIME 指令,第二条包含43 条指令,总数是100条指令。而与我们期待的结果,100条消息的结果有偏差,这说明 TCP 发生了粘包。
客户端运行结果如下
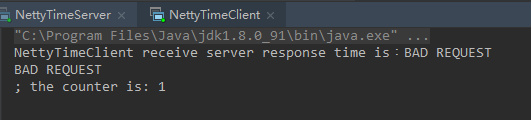
在设计上,客户端应当收到服务端100条时间消息的响应,但是实际上只收到了1条消息响应。不难理解,结合上面的服务端运行结果可知,因为服务端只收到了两条消息请求指令,由于请求条件不满足指定的指令,所以服务端返回了2条 “ BAD REQUEST ”,而实际上客户端只收到了一条包含了2条 “BAD REQUEST” 的消息,说明 服务端响应的消息也发生了粘包。
4.3、利用 LineBasedFrameDecoder 解决 TCP 粘包问题
4.3.1、支持TCP 粘包的TimeServer
1 | public class NoStickyNettyTimeServer { |
在服务端的代码中 ChannelInitializer 的 initChannel 方法,增加 LineBasedFrameDecoder、StringDecoder 两个解码器。而在 NoStickyServerHandler 中,可以直接接收 客户端的消息 msg,不需要处理半包读写,以及消息编码问题。
4.3.2、支持TCP 粘包的TimeClient
1 | public class NoStickyNettyTimeClient { |
同样地,客户端也增加 LineBasedFrameDecoder、StringDecoder 两个解码器
最终的运行结果:
最终的运行结果是符合预期,服务端和客户端均分别收到了100请求消息和响应消息。
4.3.3、LineBasedFrameDecoder 和 StringDecoder 的原理分析
LineBasedFrameDecoder 的工作原理是依次变量 ByteBuf 的可读字节,判断是否存在 “\n”、“\r\n”,如果有,则以此位置结束,从可读索引到结束位置区间的字节就组成了一行。他是以换行符作为结束标志的解码器,支持携带结束符或不携带结束符两种解码方式,同时支持配置单行最大长度。如果连续读取到最大长度仍然没有发现换行符,则抛出异常,同时忽略之前读到的异常码流。
StringDecoder 的功能很简单,就是将接收到的对象转换成字符,并调用后面的 handler。LineBasedFrameDecoder+ StringDecoder 组合就是按行切换文本解码器,它被设计用来支持 TCP 的粘包和拆包。
五、分隔符和定长解码器的应用
TCP 以流的方式传输数据,上层应用协议为了方便对消息区分,采用如下4种方式:
- 消息为固定长度,累计读取到的长度总和为定长 LEN 的报文后,就认为读取到一个完整的消息;将计数器复位,重新开始下一个数据报。
- 将回车换行符作为消息结束位置,如FTP 协议,这种方式在文本协议应用广泛
- 将特殊的分隔符作为消息的结束标志,回车换行就是一种特殊的结束分隔符。
- 通过在消息头定义长度字段来标识消息的总长度。
在 Netty 中,对上面4种应用做了统一抽象,提供了 4 种解码器来解决对应的问题。
5.1、DelimiterBasedFrameDecoder 应用开发
使用 DelimiterBasedFrameDecoder 可以自动完成以分隔符作为码流结束标识的消息解码。
5.1.1、DelimiterBasedFrameDecoder 服务端代码
1 | public class EchoServer { |
值服务端代码中,主要是创建 DelimiterBasedFrameDecoder 对象并增加到 ChannelPipeline 中。DelimiterBasedFrameDecoder 有多个构造方法,例程中,我们传递了两个参数,一个为 1024,表示单条消息最大长度,当达到最大长度仍然没有查找到分隔符,就会抛出 TooLongFrameException 异常,防止由于异常码流缺失分隔符导致内存溢出,这是 Netty 解码器可靠性保护;第二个参数为分隔符的缓冲对象。
5.1.2、DelimiterBasedFrameDecoder 客户端代码
1 | public class EchoClient { |
与服务端一样,创建 DelimiterBasedFrameDecoder 对象并增加到 ChannelPipeline 中。然后循环发送消息到服务端。
最后运行结果如下:

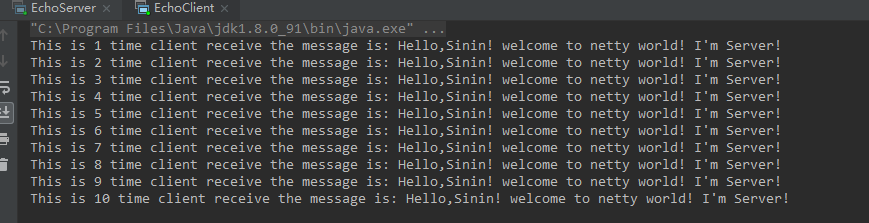
5.2、FixedLengthFrameDecoder 应用开发
FixedLengthFrameDecoder 是固定长度的解码器,它能够按指定长度对消息进行解码,开发者不需要考虑 TCP 粘包/拆包问题。
5.2.1 、FixedLengthFrameDecoder 服务端
在服务端的 ChannelPipeline 中增加 FixedLengthFrameDecoder 长度为 20 ,代码如下:
1 | public class FixedLenFrameServer { |
使用固定长度解码器 FixedLengthFrameDecoder , 无论一次接收到多少数据报,都会按照构造函数中设置的固定长度进行解码,如果是半包消息,会缓存半包消息等待下一个包到达后再进行拼包,直到读取到一个完整的包。
5.2.2、使用 telnet 命令测试 FixedLenFrameServer 服务
同 cmd 打开命令窗口,输入telnet localhost 8082 命令,连接 FixedLenFrameServer 服务。
telnet 连接成功后通过CTRL + ]打开 设置界面,通过 set localecho 命令开启本地回显。
输入如下内容
服务端收到的内容,发现完全符合FixedLengthFrameDecoder 定长解码器按照20 个字节长度对请求消息进行截取。

六、编解码技术
基于Java 提供的对象输入/输出流 ObjectInpuStream、ObjectOutputStream,可以直接把 Java 对象作为可存储的字节数组写入到文件,也可以传输到网络上。基于 JDK 默认的序列化机制可以避免操作底层的字节数组,从而提升开发效率。
Java 序列化对象的目的:
- 网络传输
- 持久化对象
**Java 对象编解码技术:**当进行远程跨进程调用时,需要把被传输的 Java 对象编码为字节数组或者ByteBuffer 对象。而当远程服务读取到字节数组或者ByteBuffer 对象时,需要将其解码为发送时的Java 对象。这被称为Java 对象编解码技术。
Java 序列化仅仅是Java 编解码技术中的一种,由于它的种种缺陷,衍生出多种编解码技术和框架。接下来会结合Netty 介绍业界主流的编解码技术和框架。
6.1、Java 序列化的缺点
Java 序列化从 JDK 1.1 就已经提供,不需要添加额外的类库,只需要继承 java.io.Serializable 接口并生成序列 ID 即可。
缺点:
- 无法跨语言
- 序列化后码流太大
- 序列化性能太低
6.2、业界主流的编解码框架
6.2.1、Google Protobuf 介绍
Protobuf 全称 Protocol Buffers,由 Google 开源而来,它将数据结构以 .proto 文件进行描述,通过代码生成工具生成对应的数据结构 POJO 对象和 Protocol 相关的方法和属性。
它的特点如下:
- 结构化数据存储格式(XML,JSON 等)
- 高效的编解码性能
- 语言无关、平台无关、扩展性好
- 官方支持 Java、C++ 和 Python
利用数据描述文件对数据结构进行说明的有点如下:
- 文本化的数据结构描述语言,可以实现语言和平台无关,适合异构系统间的集成。
- 通过标识字段的顺序,可以实现协议的向前兼容。
- 自动代码生成,不需要手工编写同样数据结构的 Java 和 C++ 版本。
- 方便后续的管理和维护。相比代码,结构化的代码和文档更易于维护。
6.2.2、Facebook 的 Thrift 介绍
Thrift 源于 Facebook,创造 Thrift 主要是解决各系统间大数据量的传输通信以及系统之间语言环境不同需要跨平台的特性。
能在多种语言之间通信,Thrift 可以作为高性能的通信中间件使用,他支持数据(对象)序列化和多种类型的RPC 服务。
Thrift 主要有5 部分组成:
- 语言系统以及IDL编译器:负责由用户给定的 IDL 文件生成相应语言的接口代码;
- TProtocol : RPC 的协议层,可选择多种不同的对象序列化方式,如 JSON 和 Binary;
- TTransport : RPC 的传输层,同样可以选择不同的传输层实现,如 socket、NIO、MemoryBuffer 等;
- TProcessor: 作为协议层和用户提供的服务实现之间的纽带,负责调用服务实现的接口;
- TServer:聚合 TProtoco、TTransport 和 TProcessor 等对象。
Thrift 支持的编解码方式:
- 通用的二进制编解码
- 压缩二进制编解码
- 优化的可选字段压缩编解码
6.2.3、JBoss Marshalling 介绍
JBoss Marshalling 是一个 Java 对象的序列化 API 包,修正了 JDK 自带的序列化包的很多问题,但又保持和java.io.Seriablizable 接口的兼容。同时增加可调参数和附加特性,并且这些参数和特性可通过工厂类进行配置。
相比传统 Java 序列化机制,其优点如下:
- 可插拔的类解析器,提供更加便捷的类加载定制策略,通过一个接口即可定制;
- 可插拔的对象替换技术,不需要通过继承方式;
- 可插拔的预定义类缓存表,可以减小序列化的字节数组长度,提升常用类型的对象序列化性能;
- 无需实现
java.io.Seriablizable接口,即可实现 Java 序列化; - 通过缓存技术提升对象的序列化性能。
相比前两种编解码框架,JBoss Marshalling 更多是在 JBoss 内部使用。
七、MessagePack 编解码
MessagePack 是一个高效的二进制序列化框架,它像 JSON 一样支持不同语言间的数据交换,但是性能更快,序列化后的码流更小。
特点:
- 编解码高效,性能高。
- 序列化后的码流小。
- 支持跨语言。
7.1 MessagePack 编解码器开发
Netty 的编解码框架可以非常方便地集成第三方序列化框架,或者自定义。
7.1.1 MessagePack 编码器开发
1 | // 继承 MessageToByteEncoder 负责将 Object 对象编码为byte 数组。 |
7.1.2 MessagePack 解码器开发
1 | // 从 ByteBuf 中获取需要解密的字节数组,通过 MessagePack 的 read 方法反序列化为相应的对象。 |
7.1.3 集成Netty 功能测试
Netty 服务端 代码如下
1 | public class MsgpackServer { |
客户端代码如下:
1 | public class MsgpackClient { |
注意:消息传输对象UserInfo 应该添加@Message 注解否则会在 MessageToByteEncoder 的 writeBytes 方法中报错
7.2、粘包/半包支持
利用 Netty 提供的 LengthFieldPrepender 和 LengthFieldBasedFrameDecoder 结合MessagePack 编解码框架,实现对 TCP 粘包/半包支持。
1 | public void bind(int port) throws InterruptedException { |
结合 MessagePack 编解码框架支持TCP 粘包/拆包问题比较简单,只需在 ChannelInitializer 的 initChannel 中添加 LengthFieldPrepender 和 LengthFieldBasedFrameDecoder即可。同样地,在客户端也应添加相应的编解码器。
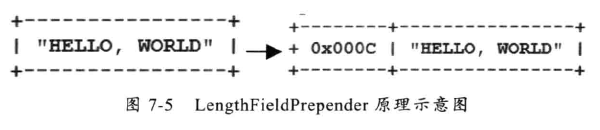
在 MessagePack 编码器之前(主要编解码器的添加顺序) 增加 LengthFieldPrepender ,它将在 ByteBuf 之前增加 2个字节的消息长度,其原理如下:
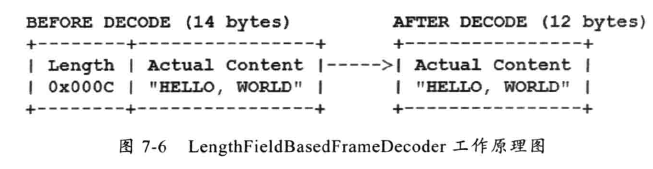
在 MessagePack 解码器之前增加 LengthFieldBasedFrameDecoder ,用于处理半包消息,这样后面 MessagePack 收到的永远是整包消息。
八、Google Protobuf 编解码
Google Protobuf 在业界非常流行,很多项目选择的Protobuf 作为编解码框架,其优点如下:
- 在谷歌内部长期使用,产品成熟度高
- 跨语言,支持多种语言,包括 C++ 、Java 和 Python
- 编码后的消息更小,更加有利于传输和存储
- 编解码性能非常高
- 支持不同协议版本的向前兼容
- 支持定义可以选和必选字段
8.1、Protobuf 入门
1、首先下载 Protobuf 编译器,下载地址为:https://github.com/protocolbuffers/protobuf/releases,选择对应平台以及版本下载,然后解压到特定的目录。把下载的文件`protoc.exe 所在的文件夹添加到环境变量。打开cmd命令行输入protoc –version ` ,如果输出版本号,说明配置成功。
protoc.exe 工具主要根据 .proto 文件生成代码。
2、创建 .proto 文件,定义数据结构(message 关键字后面跟上消息名称)
syntax = “”
message xxx {
// 字段规则:required -> 字段只能也必须出现 1 次
// 字段规则:optional -> 字段可出现 0 次或1次
// 字段规则:repeated -> 字段可出现任意多次(包括 0)
// 类型:int32、int64、sint32、sint64、string、32-bit ….
// 字段编号:0 ~ 536870911(除去 19000 到 19999 之间的数字)
字段规则 类型 名称 = 字段编号;
}
分别新建SubscribeReq和SubscribeResp 两个 proto 文件,代码如下。
1 | syntax = "proto3"; |
注意:1、protobuf2 和 protobuf3 语法不同, protobuf3 仅仅支持 repeated 字段,如果使用 optional 、required 编译会报错; 2、java_outer_classname 中的名字和 message中的名字不能重名,否则会报 protobuf matches the name of one of the types declared inside it 错误。
最终通过 idea protobuf 插件或者直接运行 protc或者通过 protobuf maven 插件 compile 编译指令得到 编译结果如下:
8.2 、Netty 的 Protobuf 服务端开发
1 | public class SubscribeServer { |
ChannelPipeline 添加 ProtobufVarint32FrameDecoder,主要用于半包处理,添加ProtobufDecoder 是用于消息的自动解码。
8.3、Netty 的 Protobuf 客户端开发
1 | public class SubscribeClient { |
九、JBoss Marshalling 编解码
JBoss Marshalling 是一个 Java 对象序列化包,对 JDK 默认的序列化框架进行了优化,但又保持了更 java.io.Serializable 接口的兼容,同时增加一些可调的参数和附加特性。
9.1、开发准备
maven 依赖 JBoss Marshalling
1 | <dependency> |
9.2、Netty 的 Marshalling 服务端开发
1 | public class MarshallingServer { |
在 ChannelPipeline 中添加 Marshalling 的 解码器以及编码器,其中SubcribeServerHandler 网络 I/O 事件处理和第8章的例程一样。
9.3、Netty 的 Marshalling 客户端开发
1 | public class MarshallingClient { |
同样的在开户端的代码中在ChannelPipeline 中也通过添加 Marshalling 的编解码器
十、HTTP 协议开发应用
10.1、HTTP 协议介绍
HTTP(超文本传输协议)是建立在TCP传输协议之上的属于应用层的面向对象的协议,其主要特点如下:
- 支持 Client/Server 模式;
- 简单—— 客户向服务器发送请求服务时,只需指定服务URL,携带必要的请求参数或者消息体;
- 灵活—— HTTP 允许传输任意类型的数据对象,传输内容类型由HTTP 消息头中的Content-Type 加以标记;
- 无状态—— HTTP协议是无状态协议,无状态是指对事务处理没有记忆能力。缺少状态意味着如果后续处理需要之前的信息,则它需要重传,这样导致每次连接传输的数据量变大。另一方面,在服务器不需要先前信息时它的应答就较快,负载较轻。
10.1.1、HTTP 协议的 URL
HTTP URL(URL 是一种特殊类型的 URI,包含了查询某个资源的足够信息)格式如下:
http://host[“:”port][abs_path]
http 表示要通过 HTTP 协议来定位网络资源;
host 表示合法的 Internet 主机域名或者 IP 地址;
port 表示一个指定的端口号,空则默认为 80;
asb_path 表示指定请求资源的 URI ;
10.1.2、HTTP 请求消息(HttpRequest)
HTTP 请求的三部分组成如下:
- HTTP 请求行;
- HTTP 请求头;
- HTTP 请求正文;
请求行以一个方法符开头,以空格分开,后面跟着请求的URI 和协议版本,格式为: Method Request-URI HTTP-Version CRLF。如:GET /netty5.0 HTTP/1.1
Method 请求方法有多种,各方法作用如下:
GET:请求获取 Request-URI 所标识的资源;
POST:在 Request-URI 所标识的资源后附件新的提交数据;
HEAD:请求获取由 Request-URI 所标识的资源的响应消息报头;
PUT:请求服务器存储一个资源,并用 Request-URI 作为其标识;
DELETE:请求服务器删除 Request-URI 所标识的资源;
TRACE:请求服务器返回所接收到的信息,主要用于诊断或测试;
CONNECT:保留将来使用;
OPTION:请求查询服务器性能,或查询与资源相关的选项和需求。
10.2、Netty HTTP 服务端入门开发
由于Netty 天生是异步事件驱动框架,因此基于NIO TCP 协议栈开发的Http 协议栈也是异步非阻塞的。
Netty 的 HTTP 协议栈无论是在性能还是可靠性上,都表现优异,非常适合在非Web 容器的场景下使用,相比传统的 Tomcat、Jetty 等 Web 容器,它更加轻量和小巧,灵活性和定制性也更好。
例程场景描述:
以文件服务器为例学习Netty 的 Http 服务端开发入门,场景如下:
文件服务器使用Http 协议对外提供服务,当客户端通过浏览器访问文件服务器时,对访问路径进行检查,检查失败时返回 403;
校验通过,以链接的方式打开文件目录,每个目录或者文件都是一个超链接,可以递归访问;
如果是目录,可以递归访问他的子目录或者文件,如果文件可读,则可以在浏览器端直接打开,或通过【目标另存为】下载文件。
1 | public class HttpFileServer { |
运行结果如下:

重点:
- 添加编码器
1 | // 负责把字节解码成Http请求 |
自定义通道处理器继承
SimpleChannelInboundHandler<FullHttpRequest>实现channelRead0方法通过
ChunkedFile将文件写入发送到缓冲区中
10.3、Netty HTTP+XML 协议栈开发
由于 HTTP 协议的通用性,很多异构系统间的通信交互采用 HTTP 协议,通过 HTTP 协议承载业务数据进行消息交互。
模拟客户订购系统示例场景:
客户填写订单,通过 HTTP 客户端向服务端发送订购请求,请求消息以XML承载放在 HTTP 消息体中。
HTTP服务端接收到客户端的订购请求后,对订单进行修改,然后通过 HTTP+XML 的方式返回响应内容。
双方采用 HTTP 协议版本 为 HTTP1.1,连接类型为CLOSE,即双方交互完成后,由服务端主动关闭链路。
10.3.1、XML绑定框架 JiBx 入门
JiBx 是一款优秀的 XML 数据绑定框架,它提供了灵活的绑定映射文件,实现数据对象与XML 文件之间的转换,不需要修改现有的Java 类。
使用 JiBx 绑定 XML 文档与 Java 对象需要分两边走:
- 生成绑定绑定 XML 文件(binding.xml) 和 数据映射文件(pojo.xml),也就是映射 XML 文件与 Java 对象之间的对应关系;
- 实现 XML 文件与 Java 实例之间的相互转换,即根据 binding.xml 生成 Marshal 或者 Unmarshal 所需的 class 文件。
首先maven 依赖如下:
1 | <dependency> |
然后编写响应的 pojo 文件,Order、Address、Customer、Shipping 等,此次不展开细说。
产生binding以及增强字节
一、产生binding.xml 文件,通过cmd 或者在idea 的Terminal 切换到项目的 target\classes 目录下,使用 jibx-tools.jar 来生成。其中jibx-tools.jar包生成xml的时候,必须这个jar包所在文件夹中包含所有的jibx其他jar包 因为在生成binging.xml时候会用到其他jar包。(如果使用maven 的包会报错)
java -cp bin;D:\jar\lib\jibx-tools.jar org.jibx.binding.generator.BindGen -b binding.xml com.study.netty.poj
o.Order
二、通过生成的binding.xml 增强字节码,生成 Marshal 或者 Unmarshal 所需的 class,如下图
此方式需要maven 依赖 jibx-tools 和 jibx-bind
1 | <dependency> |
1 | public class GenBindFileTool { |
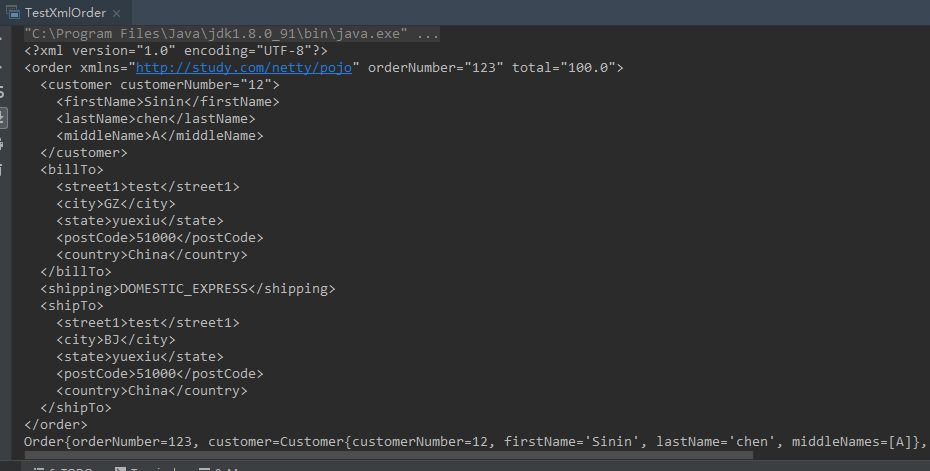
最后编写测试程序TestXmlOrder,代码如下:
1 | public class TestXmlOrder { |
运行结果如下:
10.3.2、HTTP+XML 编解码框架开发
下面将会通过商品订购流程来实现 HTTP+XML 协议栈的开发,其中流程图如下:

步骤大概有:
- 在客户端构造订购消息,并将消息编码为 HTTP+XML 格式,通过 HTTP 协议栈发送HTTP请求消息
- 服务端接收 HTTP+XML请求消息进行解码,解码成请求POJO
- 服务端构造应答消息并编码,通过 HTTP+XML 方式返回个客户端
- 客户端对 HTTP + XML 响应消息进行解码,解码成响应的POJO
由上可知,共应该需要 4 个编解码器,分别是客户端 请求时对消息的编码器和接受响应消息时的解码器;服务端接收请求消息的解码器和响应消息时的编码器。
1、HTTP + XML 请求消息编解码码类
因为请求消息编码和响应消息编码都需要用到编码器,需要抽象一个编码器供具体的类来实现。同样的解码器也需要封装抽象
1 | // XML 编码器 |
2、服务端 HTTP+XML 编解码器开发
1 | // 请求消息编码器 |
在服务端的代码中,实现HTTP+XML 自动编解码,其核心主要是请求消息的解码器和响应消息编码器的实现,并且把边编解码器添加到 pipeline 中。
3、客户端 HTTP+XML 编解码器开发
1 | // 服务端接收请求解码器,把XML 消息通过Jibx 解码为指定的消息体实例 |
与服务端代码类似,需要实现编解码器并且添加到 pipeline 中,最终的运行效果如下:
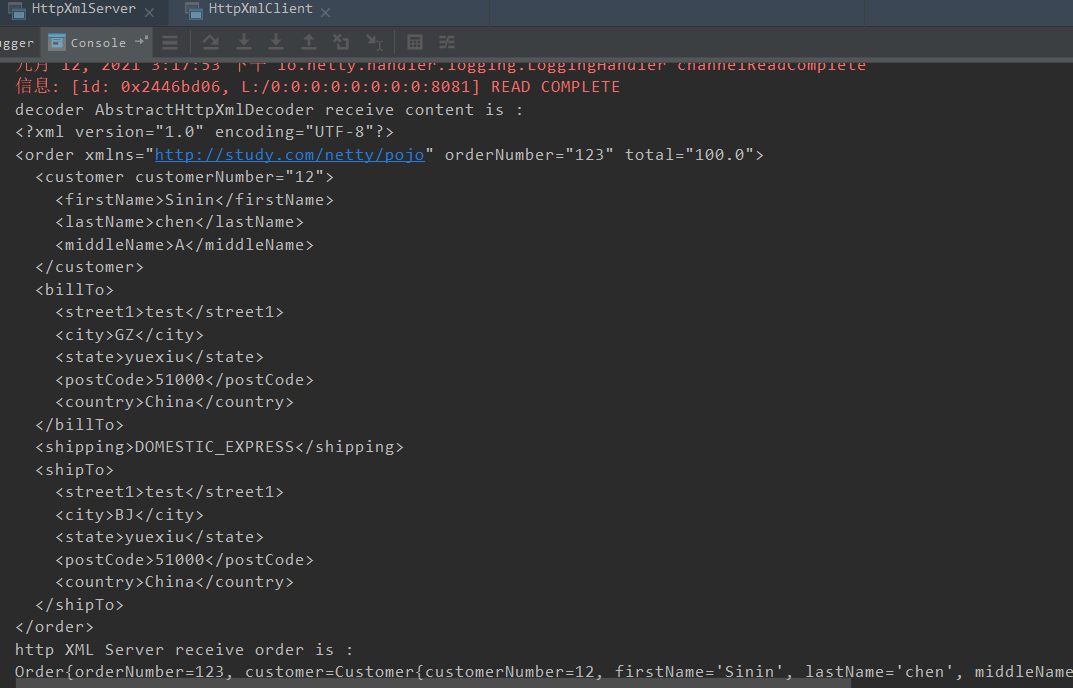
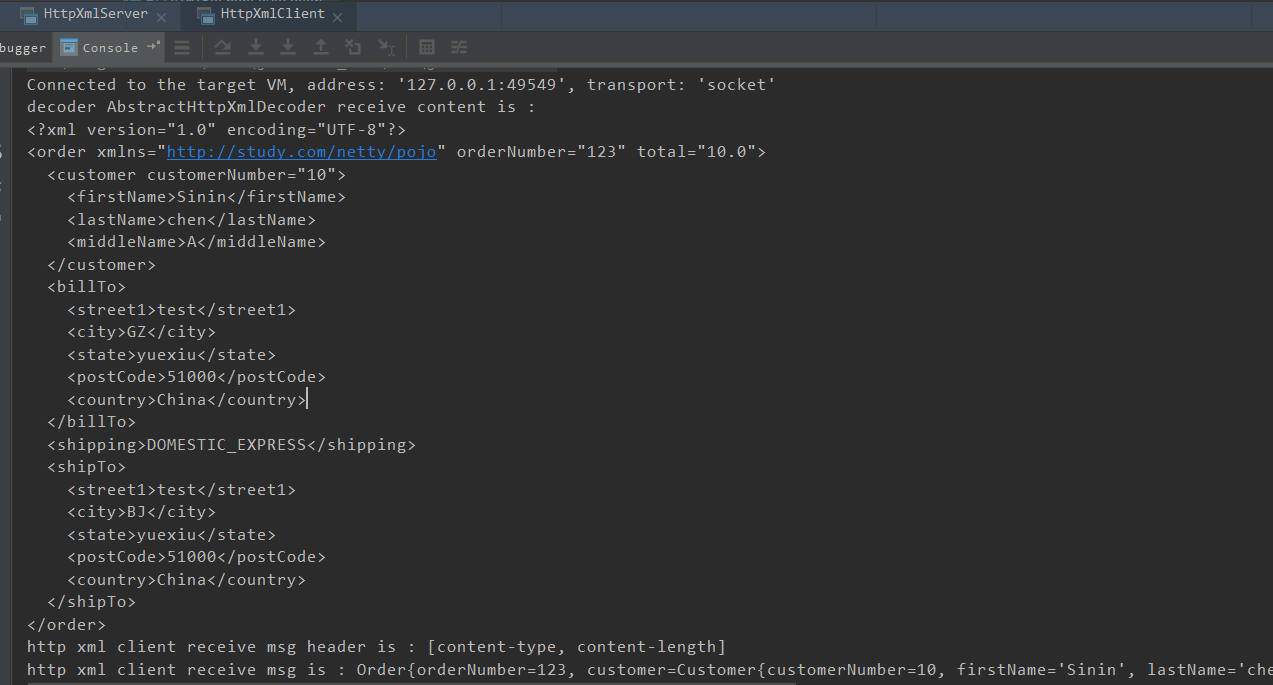
10.4、Netty HTTP+JSON 协议开发
在接下来的例程中,使用了 fastjson 框架来实现 json 的序列化以及反序列化
与 HTTP+XML 类似的,客户端和服务端同样需要实现自定义的编解码器,在编解码器中需要用fastjson 来实现序列化和反序列化,其中代码实现如下:
10.4.1、HTTP+JSON 协议栈服务端以及编码器的实现
1 | /** |
10.4.2、HTTP+JSON协议栈客户端和编解码器开发
1 | /** |
10.4.3、运行效果
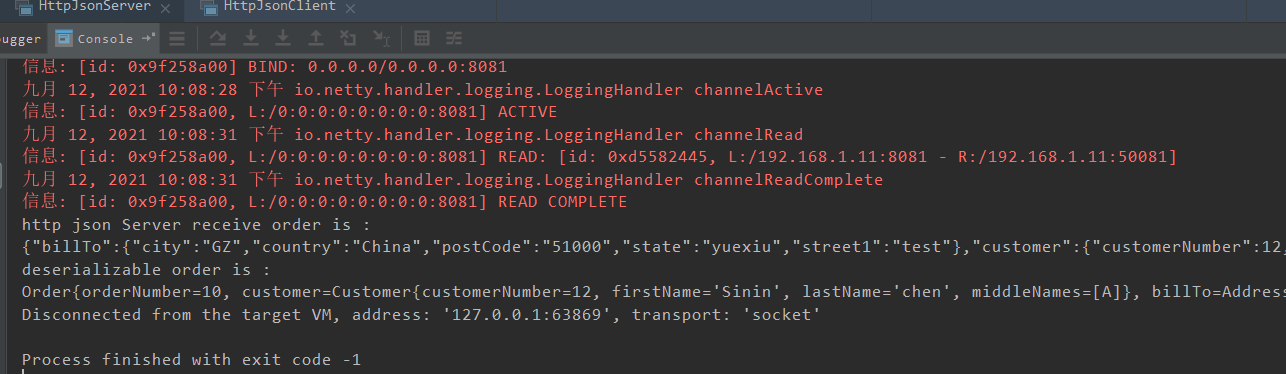
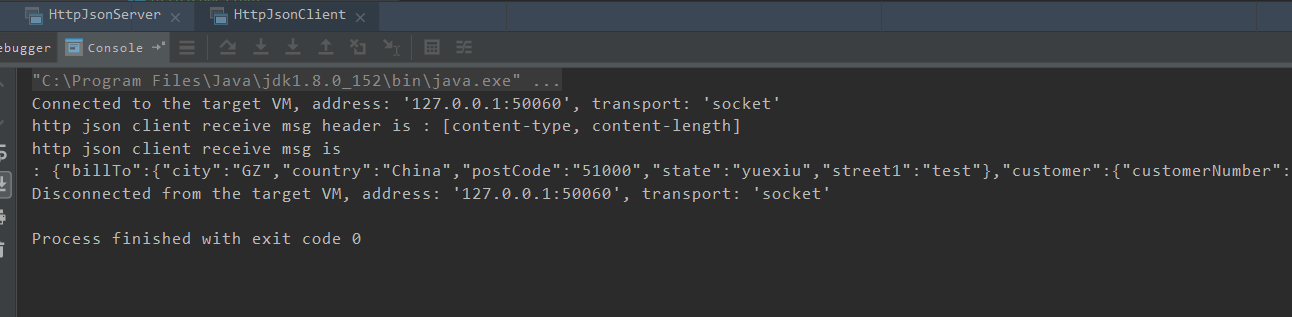
十一、WebSocket 协议开发应用
11.1、HTTP 协议的弊端
HTTP 协议的弊端主要如下:
- HTTP协议为半双工协议。半双工协议是指数据可以在客户端和服务端两个方向上传输,但是不能同时传输。意味着在同一时刻,只有一个方向的数据在传输。
- HTTP消息冗长而繁琐。HTTP 消息包含消息头、消息体和换行符等,通常情况下采用文本传输,相比其他二进制通信协议,冗长而繁琐。
- 针对服务器推送的黑客攻击,比如长轮询。
11.2、WebSocket 入门
WebSocket 是 HTML5 开始提供的一种浏览器和服务器间进行全双工通信的网络技术,WebSocket 设计出来的目的就是要取代轮询和 Comet 技术,使得客户端浏览器具备像C/S 架构下桌面系统一样的实时通信能力。其于2011年被 IEFE 定为标准 RFC6455,WebSocket API 被 W3C 定位标准。在WebSocket API 中,浏览器和服务端只需做一个握手动作,然后就可以快速建立通信通道,接着互相传递数据。
特点:
- 单一的TCP 链接,采用全双工模式通信
- 对代理、防火墙和路由透明
- 无头部信息、Cookie 和身份验证
- 无安全开销
- 通过
Ping/Pong帧保持链路激活 - 服务器可以主动传递消息给客户端,无需轮询。
11.2.1、WebSocket 链接建立
建立 WebSocket 链接时,需要客户端浏览器向服务器发起握手请求,其中该请求为一个HTTP 请求。该请求与一般的HTTP 请求不同,包含了一些附加头部信息。其中附件头Upgrade:websocket 表明这是一个申请协议升级的HTTP 请求。同时请求头消息中还包含了Sec-WebSocket-Key ,这是随机字符串信息,服务端会根据这些信息构造一个 SHA-1 的信息摘要,把 Sec-WebSocket-Key 加上一个魔幻字符串,使用 SHA-1 加密,然后进行 BASE-64 编码,将结果作为Sec-WebSocket-Accept 头的值,返回给客户端。
请求头响应头如下图


11.2.2、WebSocket 生命周期
握手成功后,服务端和客户端就可以通过message 的方式进行通信,一个消息可以由一个或多个帧组成,WebSocket 并不一定特定对应一个网络层的帧,他可以被分割成多个帧或被合并。
帧都有自己对应的消息类型,属于同一个消息的多个帧具有相同类型的数据。
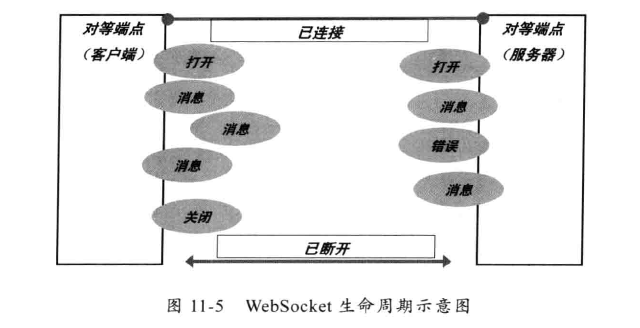
11.2.3、WebSocket 链接关闭
为关闭 WebSocket 连接,客户端和服务端需要一个安全的方法关闭底层TCP 连接和 TLS回话。如果合适,丢弃任何可能已经接收的字节,必要时(受到攻击)可以通过任何手段关闭连接。
底层 TCP 连接,在正常情况下,应首先由服务器关闭。异常情况下,可由客户端发起 TCP Close,因此,当服务器被指示关闭 WebSocket 连接时,它应立即发起一个TCP Close 操作,客户端应该等待服务器的 TCP Close 。
11.3、Netty WebSocket 协议开发
Netty 基于 HTTP 协议栈开发了 WebSocket 协议栈,利用 Netty 的 WebSocket 的协议栈可以非常方便的开发出 WebSocket 的服务端和客户端。
下面将通过一个小例程来实现 Netty WebSocket 的客户端和服务端的开发,其主要功能为:客户端发送消息到服务端,服务端对请求消息进行判断,如果是合法的 WebSocket 消息,则响应返回 Netty WebSocket 服务端消息以及时间。
11.3.1、WebSocket 服务端开发
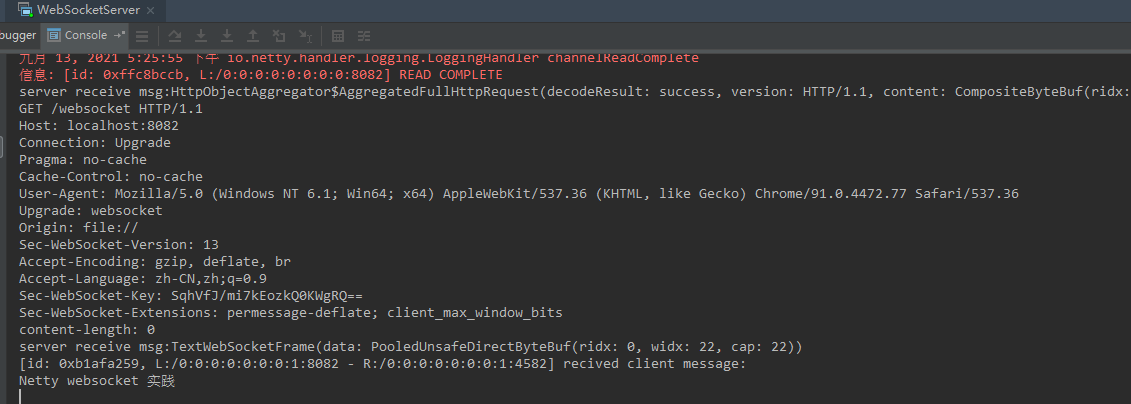
利用Netty 开发WebSocket 服务端的关键是网络 I/O 事件处理器handler,其中在 handler 处理的事件有:
- 判断区分 HTTP请求和 WebSocke 请求,因为第一次请求握手消息是由HTTP 协议承载;
- 如果是 HTTP 握手请求,则根据通过握手工厂类
WebSocketServerHandshakerFactory创建握手处理类WebSocketServerHandshaker实例;其中握手处理了中的handshake方法会将 websocket的编辑码类动态的添加到 ChannelPipeline - 链路建立成功后,客户端提交文本到服务端,服务端分别判断,是否是关闭连接、是否为 ping 指令消息,是否是支持的文本消息,然后做出响应,返回给客户端。
代码如下:
1 | public class WebSocketServer { |
运行效果如下
11.4、Netty UDP 协议开发
用户数据报协议(User Datagram Protocol,UDP)是一种传输层协议。在 TCP/IP 网络中,它与 TCP 协议一样用于处理数据包,是一种无连接的协议。
TCP 协议在进行数据传输时,需要建立连接,并且每次传输的数据都需要进行确认。当不再进行传输数据时,还需要断开连接。这样做虽然安全,但是效率较低。而 UDP 协议正好避免了这些过程,它是一种没有复杂控制,提供面向无连接的通信服务协议。
UDP 协议具备以下特点:
- 没有各种连接:在传输数据前不需要建立连接,也避免了后续的断开连接。
- 不重新排序:对到达顺序混乱的数据包不进行重新排序。
- 没有确认:发送数据包无须等待对方确认。因此,使用 UDP 协议可以随时发送数据,但无法保证数据能否成功被目标主机接收。
11.4.1、UDP 服务端开发
1 | public class NettyUdpServer { |
11.4.2、UDP 客户端开发
1 | public class NettyUdpClient { |
十二、私有协议栈开发
广义上区分,通信协议可以分为共有协议和私有协议。由于私有协议的灵活性,和时候在公司或者组织内部使用,按需定制,升级方便,灵活性好。绝大多数私有协议传输层基于TCP/IP,利用 Netty 的 NIO TCP 协议栈可以非常方便地进行私有协议的定制和开发。
12.1、私有协议介绍
私有协议本质上是厂商内部发展和才有的标准,除非授权,其他厂商一般无权限使用该协议。私有协议具有封闭性、垄断性、排他性等特点。其设计初衷并非是为了垄断,而主要是为了解决企业软件系统各个模块之间的跨节点通信问题。
在 Java 传统应用中,通常使用以下4中方式进行跨节点通信。
- 通过 RMI 进行远程服务调用
- 通过 Java 的 Socket+Java 序列化方式进行跨节点调用
- 利用一些开源的 RPC 框架进行远程服务调用,如 Facebook 的 Thrift 、Apache 的 Avro 等
- 利用标准的公有协议进行跨节点服务调用,如:HTTP+XML、RESTful + JSON、WebService 等。
跨节点的远程服务调用,除了链路层的物理连接外,还需要对请求和响应消息的编解码。在请求和应答消息之外,还需要携带一些其他控制和管理指令。如链路的握手请求和响应消息、链路检测的心跳消息等。这些功能组合到一起,就形成了私有协议。
事实上,私有协议并没有标准的定义,只要能拥有跨进程、跨主机数据交换的非标准协议,都可以被称为私有协议。
12.2、Netty 协议栈功能设计
Netty 协议栈用于内部各模块之间的通信,它基于TCP/IP 协议栈,是一个类HTTP协议的应用层协议,相比传统的标准协议栈,它更加轻巧、灵活和实用。
12.2.1、网络拓扑图
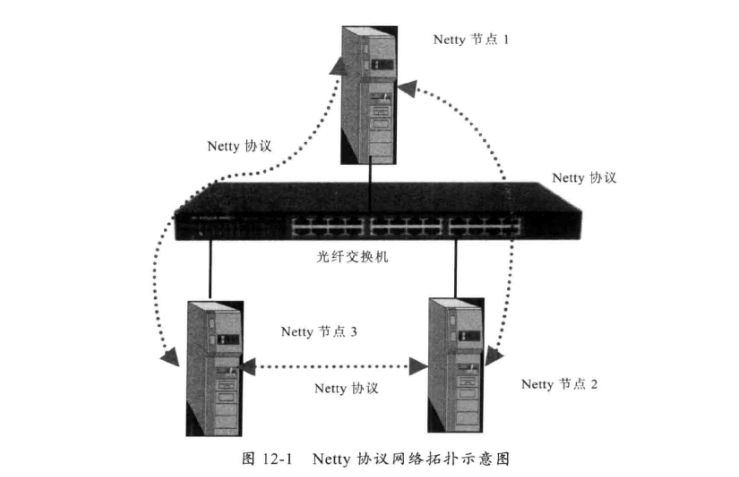
- 每个Netty 节点(Netty 进程)之间建立长连接, 使用 Netty 协议进行通信。
- 一个Netty 节点既可以作为客户端连接另外的Netty节点,也可以作为Netty服务端被其他Netty 节点连接。
12.2.2、协议栈功能描述
Netty 协议栈承载了业务内部各模块之间的消息交互和服务调用,它的主要功能如下:
- 基于Netty 的 NIO 通信,提供高性能异步通信能力
- 提供消息编解码框架,实现 POJO 的序列化和反序列化
- 提供基于IP地址的白名单接入认证机制
- 链路的有效性验证机制
- 链路断连重试机制
12.2.3、通讯模型
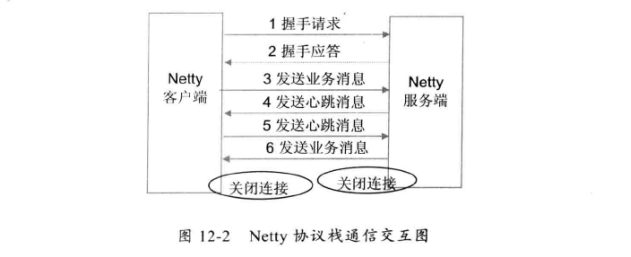
- Netty 协议栈客户端发送握手请求消息,携带节点 ID 的有效身份验证信息;
- Netty 协议栈服务端对握手请求消息进行合法性校验,包括节点 ID 有效性校验、节点重复登录校验和 IP地址合法性校验;
- 链路建立成功后,客户端发送业务消息
- 链路建立成功后,服务端发送心跳消息
- 链路建立成功后,客户端发送心跳消息
- 链路建立成功后,服务端发送业务消息
- 服务端退出关闭连接,客户端感知对方关闭连接,客户端被动关闭连接
注意:双方的心跳采用 Ping-Pong 机制
12.2.4、消息定义
Netty 协议栈的消息主要有两部分
- 消息头
- 消息体
消息结构如下:
1 | /** |
消息头定义如下:
1 | /** |
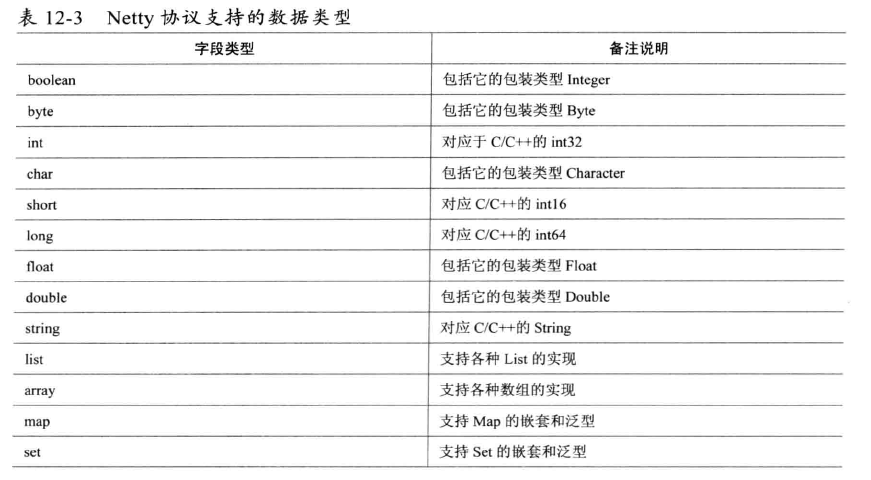
12.2.5、Netty 消息字段支持的类型
12.2.6、Netty 协议的编码规范
对于NettyMessage 的编码,根据具体的数据类型调用 ByteBuffer 的方法来编码,如果请求头 header 的 int类型数据 crcCode 可以分别通过 ByteBuffer.putInt 和ByteBuffer.getInt来编解码,byte 类型数据 如 type 可以分别通过ByteBuffer.put和 ByteBuffer.get来实现编解码。
对于请求头中的 attachment 拓展属性字段数据的编解码的操作步骤相对多一些。它的编码规则首先判断是否有数据,如果不存在数据则写入编码长度 0,ByteBuffer.putInt(0),如果有数据则写编码长度 ByteBuffer.putInt(attachment.size())。然后再对 key 编码,先编码长度,再编码 key 值数据。具体代码如下:
1 | // attachment 编码过程 |
12.2.7、链路的建立
不区分客户端和服务端,一个节点既可以作为服务端也可以作为客户端,根据具体情况而定,先发起请求调用的一方节点作为客户端,被调用的作为服务端。
为了安全,使用基于 IP 地址黑白名单校验机制,如果有多个IP,通过逗号分割。实际商用环境可以通过密钥对用户名和密码加密以增加安全性。
12.2.8、链路的关闭
由于采用长链通信,在正常的业务运行期间,双方通过心跳和业务信息维持链路,任何一方都不需要主动关闭连接。
但是,以下情况,客户端和服务端需要关闭连接。
- 当对方宕机或者重启时,会主动关闭链路,另一方读取到操作系统的通知信号,得知对方 RESET 链路,需要关闭连接,释放自身的句柄等资源。由于采用 TCP 全双工通信,通信双方都需要关闭连接,释放资源。
- 消息读写过程,发送 I/O 异常,需要主动关闭连接
- 心跳消息读写过程发生 I/O 异常,需要主动关闭连接
- 心跳超时,需要主动关闭连接
- 发送编码异常等不可恢复错误是,需要主动关闭连接。
12.2.9、可靠性设计
可能会遇到恶劣的网络环境,如网络超时、闪断、或对方进程僵死等,为保证能在这种极端的网络环境下正常运行和自动恢复,我们需要对协议的可靠性进行设计和规划。
心跳机制
在业务低谷时段,如果发生网络闪断、连接被Hang 住等网络问题时,由于没有业务消息,应用进程很难发现。到业务高峰期,会发送大量的网络通信失败,严重会导致一段时间内进程无法处理业务信息。
为解决这个问题,在网络空闲时采用心跳机制来检测链路的互通性,一旦发现网络故障,立即关闭网络,主动重连。
设计思路:
- 当网络处于空闲状态持续时间达到 T 时,客户端主动发送 Ping 心跳消息给服务端。
- 如果下一个周期 T 到来时客户端没有收到对方发送的 Pong 心跳应答消息或者读取到服务端发送的其他业务消息,则心跳失败计数器加1。
- 每当客户端接收到服务的业务消息或者 Pong 应答消息是,将心跳失败计算器清零; 连续 N 次没有接收到服务器端的 Pong 消息或者业务消息,则关闭链路,间隔 INTERVAL 时间后发起重连操作。
- 服务端网络空闲状态时间达到 T 后,服务端将心跳失败计数器加1,;只要接收到客户端发送的 Ping 消息或者其他业务消息,计数器清零。
- 服务端连续 N 次没有接收到客户端的 Ping 消息或者其他业务消息,则关闭链路释放资源,等待客户端重连。
重连机制
如果链路中断,等待 INTERVAL 时间后,客户端发起重连操作,如果重连失败,间隔周期 INTERVAL 后再次发起重连,直到重连成功。间隔 INTERVAL 时间再发起重连主要是保证句柄资源能够及时释放。
重复登录保护
当客户端握手成功之后,在链路正常状态下,不允许客户端重复登录,防止客户端在异常状态下反复重连导致句柄资源被耗尽。
服务端接收到客户端的握手请求消息后,首先对 IP 地址进行合法性校验,如果校验成功,在缓存地址表查看客户端是否已经登录,如果已经登录,则拒绝重复登录。
为了防止有服务端和客户端对链路状态理解不一致导致客户端无法握手成功的问题,当服务端连续 N 次心跳超时之后需要主动关闭链路,清空改客户端的地址缓存信息,保证后续该客户端可以重连成功,防止被重复登录保护机制拒绝掉。
消息缓存重发
无论客户端还是服务端,当链路发生中断之后,在链路恢复之前,缓存在消息队列中待发送的消息不能丢失,等链路恢复之后,重新发送这些消息,保证链路中断期间消息不丢失。
12.3、Netty 协议栈开发
12.3.1、数据结构定义
自定义消息体数据结构定义如下:
1 | public class NettyMessage { |
握手请求、握手应答、心跳检测消息都可以通过该消息结构来承载,所以不需要单独定义独立的数据结构。
12.3.2、消息编解码
在例程中,消息的编解码分别使用 NettyMessageEncoder和NettyMessageDecoder 来处理,其实现如下:
1 | // 自定义编码器 |
其中使用了 Marshalling 来处理对象序列化和反序列化,其代码如下
1 | // 自定义的 Marshalling 编码器 |
12.3.3、握手和安全认证
客户端握手认证
握手认证是在客户端和服务端成功建立TCP通信激活时,发送握手请求给服务端,代码如下:
1 | public class ClientMsgHeaderHandler extends ChannelInboundHandlerAdapter { |
服务端代码
1 | public class LoginAuthRespHandler extends ChannelInboundHandlerAdapter { |
经过与客户端TCP三次握手成功后,客户端发送握手认证消息给服务端,服务端根据消息类型判断,如果是握手认证消息,则判断是否已经登录并且是否在白名单配置中,如果通过则构造握手响应消息返回给客户端。
12.3.4、心跳检测
握手成功后,在客户端接收到服务端响应的握手成功消息后。客户端主动发起心跳消息,服务端收到客户端心跳消息后,返回心跳应答,在此过程中,心跳消息主要是检测链路的可用性,不需要携带消息体。
1 | // 客户端心跳请求代码 |
在客户端接收到握手成功的响应消息后,响应信息通过 Handler 继续向下传递,HeartBeatReqHandler 接收到消息,判断如果是握手成功,则启动无限循环定时器发送心跳消息。NioEventLoop 是一个 Schdule,因此支持定时器的执行。心跳第定时器很简单,通过构造参数获取 ChannelHandlerContext 发送消息。
在服务端接收到心跳消息则返回心跳应答即可。
心跳超时很简单,利用 Netty 的 ReadTimeOutHandler 机制,一定周期内没有读取到对方消息时,需要主动关闭客户端连接。如果是客户端,重新发起连接;如果是服务端,释放资源,清除客户端登录缓存,等待客户端重连。
12.3.5、断连重试
在客户端中,感知到断连后,释放资源,重新发起连接。
1 | ChannelFuture future = bootstrap.connect(new InetSocketAddress(host,port) |
监听网络断连事件,如果 Channel 关闭,则自行后续重连任务,通过 Bootstrap 重新发起连接。客户端挂在closeFuture 上监听链路关闭信号,一旦关闭,则创建重连定时器,5s 重新发起连接,直到连接成功。
12.3.6、客户端代码
1 | public class NettyClient { |
12.3.7、服务端代码
1 | public class NettyServer { |
12.4、运行协议栈结果


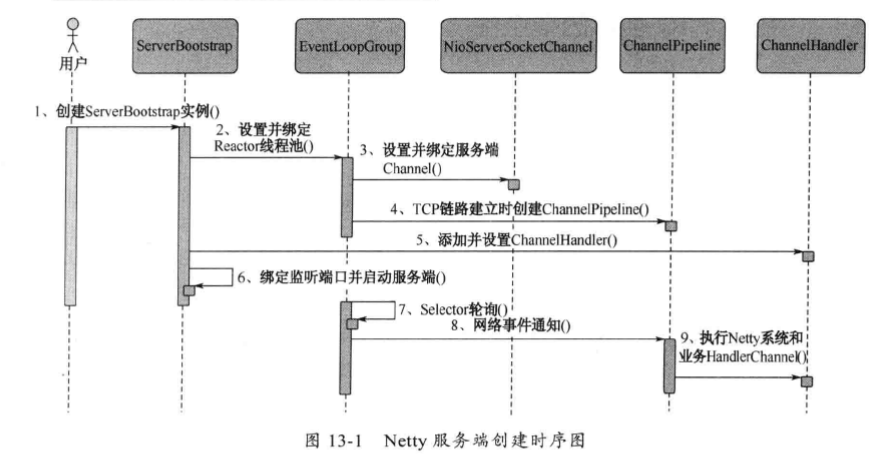
十三、服务端创建
13.1、服务端创建流程